
Service returned to normal within 15 minutes and delivery has remained consistent
11/21/2024 02:33 AM 2 days
We are noticing network latency which is causing delivery delays of up to 5 minutes on average. We're working with our network providers to diagnose the issue but it appears to impact more than just our services
Tonight, November 15, 2024, we will be testing a new high-availability system to enhance the reliability of login.exchangedefender.com. During this process, we will actively monitor the service to ensure it remains accessible.
You may experience brief interruptions as we simulate various scenarios. However, any downtime is expected to last no more than three minutes per instance.
If you encounter persistent issues unrelated to service availability, please clear your browser cookies to reset your authentication state.
We appreciate your understanding and patience as we work to improve our systems.
Support portal and Service Manager services are back online. Thank you for your patience during this urgent maintenance cycle.
P.S. Thank you for reaching out via www.exchangedefender.com web site Live Chat as well.
11/15/2024 17:31 PM 8 days
We have been forced to run an urgent maintenance cycle on our support portal at https://support.exchangedefender.com and for the moment the access to support or service management will not be available, you will see the following notification.
maintenance underway.. please check back in a few minutes
Tuesday, November 12h we experienced an issue inside our load balancing infrastructure which lead to several services not responding. Users were unable to trigger releases of messages from email reports but were able to do so via https://admin.exchangedefender.com
The issue was resolved shortly before 8AM EST and all web services are now available.
We were able to confirm Exchange is loading correct certificates, all customer branded SSL certificates are now loaded correctly.
P.S. This is why we went away from custom client-branded SSL certificates, the little bit of extra vanity isn't worth the potential performance problems.
09/16/2024 14:38 PM 7 days
Mobile devices are currently receiving SSL errors such as "cannot verify server identity" or "certificate not trusted" due to the wrong certificate being loaded.
We are working on the issue and expect to have it resolved shortly. In the meantime, you can still access email on your mobile devices by opening Safari or Chrome on your phone and going to https://owa.xd.email/owa/
As of 6 PM EST all services are confirmed as recovered. We're sorry about the inconvenience this outage caused.
07/10/2024 21:26 PM 12 days
Services are currently recovering, we are confirming and monitoring all the services and will report when everything returns to green (MTTR 30 minutes)
07/10/2024 20:09 PM 12 days
We are currently experiencing a network outage and are working with upstream providers (issue related to the Hurricane Beryl)
We're moving around workloads in an effort to restore all services as fast as possible, ETA on network recovery is approximately 20 minutes (4:30 PM EST)
Access has been restored and we are seeing successful connections
05/23/2024 17:12 PM 25 min
We are currently working on the problem related to Microsoft Exchange storage systems. If you go to OWA or Outlook you will be greeted with this error after authentication: "We're having trouble getting to your mailbox right now. Please refresh the page or try again later."
The problem is currently affecting up to 60 mailboxes that are showing as offline and we're allowing automatic recovery to take place. Not to worry, no mail is lost and we will have the mailboxes online as soon as possible.
Because we cannot provide an ETA we encourage everyone affected to go to https://admin.exchangedefender.com and click on Inbox. This is our new business continuity solution designed for moments like this one - you can send and receive email in realtime until Outlook/OWA service is restored.
As noted in our blog we have increased our geographical footprint and activated one of our newest data centers. So far the only issues we've noted is with Office365 users who haven't fully trusted our network. O365 defers connections from previously unseen IPs unless the IP is trusted in the tenant settings.
If you see "Deferred: 451 4.7.500 Server busy. Please try again later from" in the mail logs on ExchangeDefender for your inbound mail please make sure you've configured all of the anti spam settings in O365
Network expansion work has been completed and our network is looking better than ever. The only casualty of the work involved ExchangeDefender's internal edge-to-edge routing infrastructure which is responsible for internal notification alerts (used for sending ExchangeDefender generated notifications such as SPAM Quarantine Reports).
All the messages have been delivered but you may have received 2-3 SPAM reports that were stuck in the queue over the weekend.
04/12/2024 02:26 AM 11 days
Over the next few days we will be expanding our network and adding more resources (related to work completed earlier this week)
In the event you notice any timeouts or disconnections (keepalive applications), they should be momentary and no data will be lost.
ExchangeDefender SPF policy authorizations experienced errors earlier today, you may have received error such as:
Email rejected: 550 65.99.255.36 is not allowed to send mail from yourdomain.com.
This issue was caused by a network translation (proxying) of outbound mail and in some instances the calls went direct instead of authorized path.
This issue has since been corrected and you should not be experiencing any problems sending email. If problems with sending email persist please open a support ticket and send an email from the affected user to postmaster@exchangedefender.net (reference tracking if possible) and we will look at it as it may be unrelated to our event.
We have pinpointed the delays and have implemented a temporary solution. Delivery times are within operating range.
04/08/2024 11:18 AM 15 days
We are seeing increasing inbound delivery times and are investigating
the migration was completed successfully and all services were verified
04/09/2024 01:08 AM 14 days
we have resumed routing inbound mail (15 mins ago) and are finalizing the changes for the rest of services
04/09/2024 00:31 AM 14 days
the change is underway and in progress
04/09/2024 00:25 AM 14 days
We are temporarily pausing inbound mail in preparation of reattempting the migration
04/09/2024 00:19 AM 14 days
The migration has been slightly postponed and services are accessible except for web services. We anticipate the changes to finalize within the next 15 minutes
04/08/2024 23:59 PM 14 days
The changes are about to go live. There will be no service access until 8:05PM as the changes finalize
04/08/2024 23:36 PM 14 days
Network changes will occur in 20 minutes. Prior to the change we will disable incoming mail in order to let the network settle after the change. We will re-enable inbound mail as soon as possible after the 8PM change.
04/03/2024 17:26 PM 20 days
On Monday April 8th at 8PM Eastern we will be making a change to our core network in our primary data center in preparation for a geographical expansion coming up. We expect there to be a brief 5 minute period where all services will be offline as our providers apply configuration changes to facilitate the expansion. If services are impacted for more than 15 minutes we will notify our providers to reverse the changes.
ExchangeDefender is making a change in relaying policy for Office365/M365 users: we are discontinuing unauthenticated relay for domains that aren't protected by ExchangeDefender. If you are sending email from your M365 tenant and the domain you are sending from is not protected by ExchangeDefender you will get the following error:
550 ExchangeDefender is not allowed to send mail on behalf of your email address.
See https://exchangedefender.com/docs/configure-outbound-smart-host-office-365#/microsoft-365-xd-outbound-limitation
The policy of relaying email on behalf of 3rd party domains (who are not protected by ExchangeDefender) dates back to late 1990s long before things like SPF and DKIM. Back in the long, long ago we allowed clients to relay mail through our network from any domain - this functionality was required for mail enabled contacts and forwarding of email was a frequent practice. We've kept that practice up with cloud deployments because sometimes internal apps and processes may send email through the tenant that routes all mail through ExchangeDefender but every sender domain isn't defined or doesn't receive email (notification services).
Unfortunately this legacy feature has become a source of network abuse and we have to shut it down. Going forward ExchangeDefender will only relay outbound email for the domains that are protected by ExchangeDefender. Any 3rd party / external domains will require a separate connector but we actively discourage you from pursuing that as those messages are nearly certain to end up in Junk/SPAM and will trigger negative domain sender reputation.
In order to continue sending from external domains you must create an IoT account and switch to outbound-auth.exchangedefender.com when relaying from Office 365
This outage does not impact ExchangeDefender but is widespread enough that we felt compelled to alert our clients. AT&T has been experiencing outages across it's network today:
If you are having issues with Internet access (email/texting/etc) and rely on AT&T, keep an eye on AT&T's outage page.
Courtesy update: There have been no further events or issues since the last update, ExchangeDefender operations are back to normal.
Thank you to all the clients and partners that opened the ticket and provided SMTP headers (or .eml/.msg files). During the first few minutes of the incident report we could not confirm or replicate the issue and we first attempted to confirm that the size of the message coming in is approximate to the size of the message going out of our network. This issue only occured on one node, one system, and was only caught by one partner in UK that manages a large email transaction business that can receive 100's of messages per second. We worked the issue backwards and located the problem within minutes.
Unfortunately, this required pausing mail flow in ExchangeDefender. All the messages have been processed and delivered, but with a delay. We did not want to risk corrupting more mail. Because this issue was occuring at the network service level (i.e., before the message is ever written to the disk) this was the only recourse and it's the first time this has happened in the company history. As a result, we will be adding a network service facility to do data duplication of incoming traffic so that it can be paused and replayed if a catastrophic event occurs between ExchangeDefender and target Inbox (more details on this soon).
Again, huge thanks to everyone that took a moment to provide SMTP header or .eml/.msg. You make it possible for us to resolve catastrophic issues within minutes instead of hours or days and we're eternally thankful for that and for your business.
02/21/2024 15:11 PM 2 days
We are restoring inbound mail flow as of 10:00 AM.
We have identified an issue in a 3rd party content parsing engine on one of our inbound processing nodes. Affected systems & software have been pulled from production for further evaluation and troubleshooting. Mail flow will be slightly delayed for a few minutes and then resume normal operations.
02/21/2024 14:44 PM 2 days
We are currently researching an urgent issue with Exchange recipients receiving messages with empty subject and empty body.
We still have not been able to reproduce or confirm the issue and at 9:35am EST we paused inbound mail processing to investigate.
We will keep you updated here.
Quarantine reports that were scheduled from Feb 13 8pm until Feb 14th 10am were inadvertently skipped and will be manually requeued for delivery
all mail has been delivered successfully
02/06/2024 04:21 AM 17 days
we have begun to process the backlog of messages from throughout the day.
Some users may have received undeliverable emails or delay notification emails which can be ignored as all messages are routing properly
02/06/2024 02:31 AM 17 days
We have been actively working on an issue impacting outbound emails from Exchange. We are setting up a new server to switch the traffic from the current edge node.
The login service has been fully restored for Service Providers, MSPs, and Domain Administrators as of 10AM.
The user access has also been restored but it's sluggish due to everyone authenticating/reauthenticating at once, we expect the sluggishness to last 10-15 minutes at which point all the login functionality will resume normal operation.
01/12/2024 14:54 PM 11 days
ExchangeDefender admin web services have had issues with user login this morning. The root cause is with the authentication (login) server and it has been addressed.
We are returning the service to normal operations, please stand by.
We will be performing upgrades in our Dallas data center from 9pm - midnight (Central time US).
The maintenance is being done on power and routing infrastructure which is highly redundant and we do not expect any service interruptions.
We can confirm that messages are moving as they should. If you received a bounce message it was informing you of the delay which was caused by the Microsoft Exchange routing / DNS. The message is notifying you of the delay and it was delivered between noon and 3PM today. We apologize for the convenience this has caused.
Here is a sample bounce message:
Delivery is delayed to these recipients or groups:
vlad@exchangedefender.com (vlad@exchangedefender.com)
Subject: Exchange DNS problem causing delays
This message hasn't been delivered yet. Delivery will continue to be attempted.
The server will keep trying to deliver this message for the next 6 days, 18 hours and 40 minutes. You'll be notified if the message can't be delivered by that time.
Diagnostic information for administrators:
Generating server: MBOX7.dal.exch.xd-mail.online
vlad@exchangedefender.com
Remote Server returned '400 4.4.7 Message delayed'
Original message headers:
Received: from MBOX5.dal.exch.xd-mail.online (192.168.170.5) by
MBOX7.dal.exch.xd-mail.online (192.168.170.7) with Microsoft SMTP Server
(version=TLS1_2, cipher=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256) id
15.1.2176.2; Thu, 12 Oct 2023 09:14:53 -0400
Received: from MBOX5.dal.exch.xd-mail.online ([fe80::a9ad:5cb1:b8e1:66c8]) by
MBOX5.dal.exch.xd-mail.online ([fe80::a9ad:5cb1:b8e1:66c8%5]) with mapi id
15.01.2176.014; Thu, 12 Oct 2023 09:14:53 -0400
Please note, this is not related to the delays experienced with Office365/Microsoft365 yesterday. which they have since resolved.
10/12/2023 19:01 PM 10 days
We identified an issue with Microsoft Exchange routing late last night that affected several users in the same user group. Due to an issue with Microsoft updates one of the network controllers was having problems contacting the correct DNS service. This issue caused some emails from some users to keep getting requeued, thus stalling outbound delivery and causing a delay.
We were able to mitigate the issue as of noon today and have confirmed that all messages have been processed and all queues are empty. The messages have been delivered but with a delay.
The issue has been resolved by Microsoft. For more details please see this article at Bleeping Computer.
10/11/2023 14:08 PM 12 days
Office365 appears to be deferring mail from our LAX data center for some deliveries with the message
4.7.500 Server busy. Please try again later
It does not appear to be occurring for all O365 destination recipients and is likely caused by an incomplete deployment where administrators may not have configured connection filtering rules and anti phishing rules
Outbound mail is again routing without error, the DDoS attack has been mitigated.
09/27/2023 19:56 PM 26 days
We've been able to mitigate the attack and are currently cleaning out messages that were part of the attack delivered to our network. After the purge is completed we anticipate restoring the service and pushing it back to general availability.
Expect an update by 4:10 PM EST.
09/27/2023 19:42 PM 26 days
We are currently addressing a wide reaching distributed denial of service (DDoS) attack with multiple compromised Microsoft/Office365 clients being used to phish gmail.com accounts. In order to prevent domain reputation problems and potential RBL listings we've had to temporarily pause routing between the two networks in order to add more inspection and containment of this attack.
Please stand by, mail will automatically resume and deliver in the background.
Completed without interrupting service
09/23/2023 16:25 PM 1 hrs
We will be taking a database offline to create an offline copy to resync members. During this period users on the offline database will be unable to access their mailbox and incoming mail will be queued. As a reminder, customers have access to inbox and livearchive
Sunday Sept 24th 12:30AM - 2:30AM
All mailboxes are available and mail is flushing
09/22/2023 00:07 AM 1 days
We are in the final stretch of the process and should have the new database ready within an hour.
09/21/2023 20:21 PM 1 days
We are still working on moving the data for the final ~30 mailboxes. We are pulling the last offsite backup for the database to our lab environment in order to have a multipath approach. We are currently aiming to have service restored by EOB Friday but we are still unable to provide a reliable ETA for at least another 12 hours.
Affected users with local Outlook instances are able to request a blank mailbox on a new database in order to allow the affected user to import their cached Outlook data into their new mailbox.
09/21/2023 09:25 AM 2 days
We have completed the required emergency storage upgrade to exchange. There are around 30 mailboxes which are still moving from their existing database. Unfortunately this move was required due to cascading hardware issues that were worsening rapidly. Unfortunately the data move for the final two databases is unpredictable as the transfer rate are fluctuating.
We will allow exchange to continue to perform repairs and copies from the existing database before we consider alternative actions.
If you need access to send and receive email immediately and don't want to wait/troubleshoot Outlook go to https://admin.exchangedefender.com and click on Inbox.
For older messages (up to 1 year) please go to LiveArchive (also accessible from https://admin.exchangedefender.com or https://livearchive.exchangedefender.com)
09/21/2023 04:35 AM 2 days
For users affected by the database outage please access inbox or livearchive to access live mail
09/21/2023 04:13 AM 2 days
upgraded severity and title
09/21/2023 04:05 AM 2 days
We still are still working on recovering access for the final two mailbox databases.
09/20/2023 23:51 PM 2 days
There are a subset of mailbox databases offline while we perform work. Access to these mailboxes will yield an error message in OWA while offline
09/20/2023 20:29 PM 2 days
Maintenance will begin at 6PM Eastern and is estimated to continue until 11PM Eastern
09/20/2023 03:00 AM 3 days
Maintenance will be rescheduled for Sept 20
09/20/2023 02:14 AM 3 days
Maintenance has not begun and will likely be rescheduled. A future update will contain the next allocated window.
09/19/2023 16:49 PM 4 days
We will be performing on site upgrades and maintenance to the Exchange cluster. Service is not expected to be impacted or affected, however, any unexpected interruption in service would be expected to be resolved within 15 minutes.
Tues September 19th 2023 6PM EASTERN until 11PM EASTERN
All databases have come online and connections have stabilized
09/13/2023 23:30 PM 9 days
We are investigating connection issues with 6 databases in our Exchange cluster
On our last webinar we announced the new ExchangeDefender reports infrastructure that relies on xdreports.com and helps improve delivery of Quarantine and new ExchangeDefender reports. If you haven't whitelisted *.xdreports.com on your server/service now would be a great time to do so
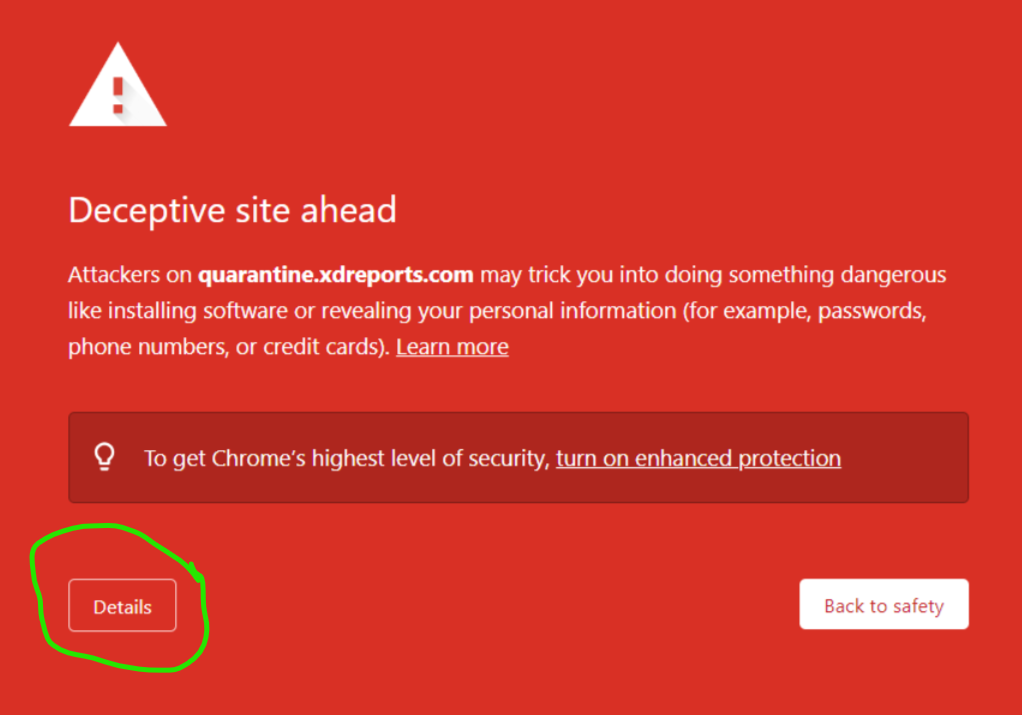
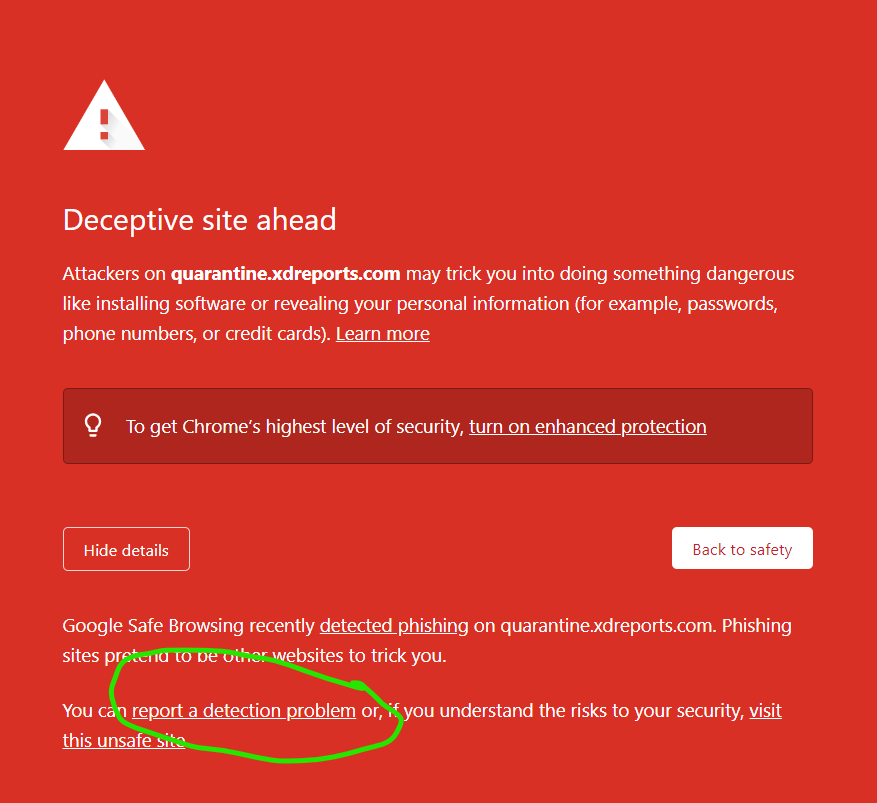
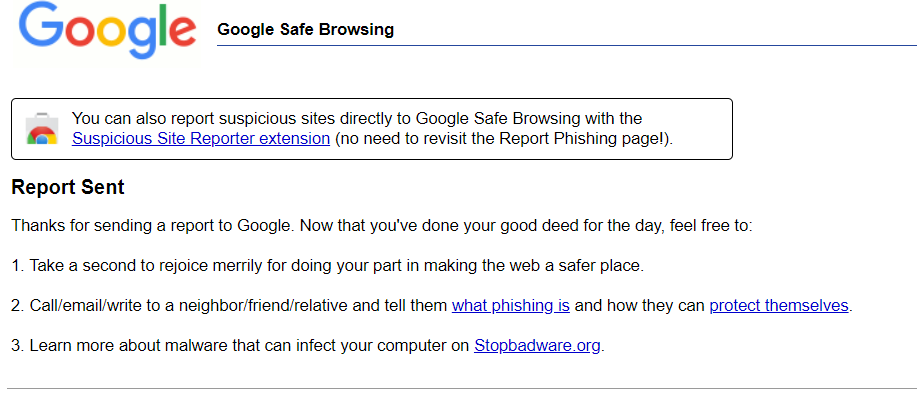
If you've experienced an issue releasing a message from ExchangeDefender today, it would be result of a data sync on the backend.
If you were unable to release the message, give it one more try. Open the email report or login at https://admin.exchangedefender.com and try releasing the message again. It should arrive within a minute!
We've got our logging services on all new gear, thank you so much for your patience and we're sorry for the inconvenience we caused.
08/25/2023 01:48 AM 29 days
ExchangeDefender is performing maintenance on our core database systems that manage our logging infrastructure. Unfortunately nearly every system in ExchangeDefender relies on logs so some web and email services will see temporary service interruptions.
We apologize for any inconvenience this causes and we're working to complete the work as fast as possible. The maintenance will be complete by midnight.
We've returned to our normal routing process and all systems have rejoined routing groups. We're sorry for the inconvenience and support activity this caused.
08/14/2023 14:47 PM 9 days
The systems impacted by this issue have been removed from the network and we've confirmed that messages that were in the queue have been scanned and delivered.
We have removed the network that caused this issue from active routing. Delivery times are not being impacted.
Details: The error command 5.7.1 was issued due to a permanent failure in the SPF framework that validates senders domains and their SPF DNS records. The issue was caused by an upstream DNS server taking too long to respond to certain requests. This issue (and the related one with admin.exchangedefender.com) were caused by an OTA update to our network switches which caused some systems not to bring up the appopriate network interfaces (leading to decreased performance leading to timeouts leading to failure leading to errors).
08/14/2023 14:15 PM 9 days
We're having an issue with SPF/DKIM detection in Dallas and regrettably a number of messages have been rejected with error code 5.7.1 as the system could not resolve the SPF record.
The network has been removed from our routing while we investigate so you should not be seeing any further errors. We will update this NOC when we bring the systems back online but in the meantime the email is routing without issue.
service has been restored and connections are successfully completing.
08/09/2023 16:05 PM 14 days
Most of the databases have mounted and we estimate the final 5 to mount in the next 5 minutes. Be mindful that all pending connections from anyone on the database will connect once their database is online and there may be a sluggish feel while the connections settle.
08/09/2023 15:27 PM 14 days
The affected node appears to be coming online and we will be monitoring it over the next 15 minutes to confirm everything settles back into sync
08/09/2023 15:16 PM 14 days
We are delaying the forceful switch another 15 minutes (11:30AM) as we're actively working with the data center staff on the original host and all signs point to a resolution incoming.
08/09/2023 14:17 PM 14 days
It appears that around 12% of the mailbox databases within Exchange are currently offline due to a node that went offline while holding an active lock on the database. We're working to bring the node up in a healthy manner so that all nodes are able to resynchronize. We will allow the node until 11:15AM (one hour) to come online before we forcefully move the databases to another node.
Back in May of 2020 (over 3 years ago) we discontinued the legacy Exchange infrastructure and retired the legacy endpoints. At the time we recommended reconfiguring Outlook and mobile devices to use a new endpoint owa.xd.email in place of the legacy ones:
cas.rockerduck.exchangedefender.com
cas.darkwing.exchangedefender.com
cas.scrooge.exchangedefender.com
If you are still connecting to these legacy hostnames 3 years after they've been decomissioned we urge you to go through the following guide: https://exchangedefender.com/docs/exchange-setup - we have done our best to support legacy deployments for as long as possible to help our partners and busy IT departments. Keeping these legacy items in place degrades the performance and security profile of our network so for everyone's safety we have no choice but to finally discontinue the legacy names. If your Outlook is reporting an error please urgently follow the steps in the guide and update your DNS/Outlook.
We will end support for old/legacy hostnames (cas.*.exchangedefender.com) in September 2023. If you are reading this notice after September 2023, you can immediately access your email at https://owa.xd.email/owa/ and follow the guide to reconfigure your DNS, Outlook, or mobile devices.
The issue has been addressed as of 3PM EST and pdf attachments are again being processed without an issue.
07/25/2023 18:06 PM 29 days
ExchangeDefender Encryption is not properly processing .pdf attachments at this time. We are working on a solution now.
If you need to securely send pdf attachments in the meantime please rely on our ExchangeDefender WebShare https://webshare.exchangedefender.com/ service which will enable you to email password protected .pdf files in the meantime while maintaining encryption (and additional password + access control).
Earlier this morning a failure in one of the core Microsoft cloud services impacted the delivery of messages. The issue was cleared out ~10AM EST and all mail has been delivered.
For future reference, if there is an impact to timely delivery of messages to Exchange you can still get your messages at https://admin.exchangedefender.com by clicking on Inbox. For more details please see https://exchangedefender.com/inbox
The issue was confirmed to be resolved. Any messages that failed with the error will successfully go through if resent by the sender.
07/05/2023 16:08 PM 18 days
From 11:30AM Eastern until 11:50AM Eastern outbound messages were rejected with "access denied" due to a misconfigured routing rule that internally routed messages to a sibling outbound server instead of the real recipient destination. The sibiling outbound server was being tested and was only intended to receive test messages which caused the rejections to occur when it received non test messages.
Based on reports this seems to only have affected customers on our Hosted Exchange cluster.
We have been able to narrow down the issue with Microsoft M365 incorrectly classifying messages as Junk mail or High Confidence Phishing. The problem has been reproduced from external senders (Gmail), from internal senders (M365->M365), and through a security service (M365->ExchangeDefender & similar ->M365).
The problem appears to be related to an undocumented Microsoft "feature" that tracks the age of URLs:
X-MS-Exchange-Organization-UrlMinimumDomainAge
The X-Header is used to track the days since the domain was registered and it appears that Microsoft is tracking threads that contain recently created URLs. There is absolutely no documentation from Microsoft on this header nor guidance on how to control it. Our own guidance is as follows:
1. Whenever possible, send plain-text messages not rich HTML. Microsoft is aggressively filtering multipart messages (attachments, inline images, threads) and the bigger the thread or more images the less likely it will end up in the Inbox.
2. Whenever possible, trim back and forth conversations entirely to just the last message.
3. Whenever possible, start a new thread instead of just hitting Reply. Microsoft is tracking message threads and the longer the thread the less likely it will end up in the Inbox.
4. Whenever you encounter an error, rely on https://bypass.exchangedefender.com
We are continuing to work with Microsoft and continue to escalate the issue.
05/25/2023 19:23 PM 28 days
The following advisory is issued based on ExchangeDefenders troubleshooting with our clients, competitors, and 3rd parties.
As of May 24th we have seen inconsistency in Microsoft's ability to reliably deliver email to M365 users Inbox. Legitimate messages are moved to M365 Junk Mail with SCL:5. So far we've been able to replicate this issue with:
-HTML messages (multipart w/ and w/o text body)
-Text only messages
-Messages from M365
-Messages outside M365
Identical message coming from an the exact same sender email address, server IP address, and to the same recipient will randomly arrive in the Junk Mail or Inbox in the same 5 minute span. It doesn't matter whether messages are coming from M365 hosted domain, through ExchangeDefender smarthost, directly via SMTP from Exchange or sendmail.
We have shared our findings with our clients and with our competitors and it appears to be affecting everyone intermittently.
We have escalted this issue within Microsoft and as of now they don't have a solution.
Based on our research and our work over the past day, the issue appears to be intermittent and isolated to M365. We believe it has to do with Microsoft updating something with it's antispam protection based on the fact that the issue can be replicated intermittently without regard for the senders email address/server/software/content.
--------------
If you're currently experiencing this problem please ask your recipients to create a trusted sender policy for the following IP ranges:
174.136.31.16/28
207.210.228.192/28
This is the only known method that works at the moment.
If your domain is protected by ExchangeDefender, send an email to postmaster@exchangedefender.net and we will escalate the issue within Microsoft/M365 on your behalf.
Admin M365: https://learn.microsoft.com/en-us/microsoft-365/security/office-365-security/create-safe-sender-lists-in-office-365?view=o365-worldwide
Outlook: https://support.microsoft.com/en-us/office/add-recipients-of-my-email-messages-to-the-safe-senders-list-be1baea0-beab-4a30-b968-9004332336ce
We are currently performing an upgrade and policy changes on our support portal to make things more efficient and secure.
During the upgrade some requests may be dropped / get a 502 timeout.
This issue has been temporarily resolved to allow operational status to resume. We will continue to monitor throughout the day and work on a full resolution in the off peak hours.
04/18/2023 16:26 PM 5 days
Around 10AM EST we started experiencing issues with our inbound15 cluster. During the shutdown/offlining sequence the network rejected messages with error:
554 inbound15.exchangedefender.com ESMTP not accepting messages
Unfortunately, this issue affected inbound mail flow but you should not be seeing additional errors regarding this as the cluster has been removed and the issue that has caused the error in the first place has already been addressed on the rest of the network.
From 8:00 PM until 8:35 PM there was a single node in our Dallas cluster which issued "550 5.7.1 Command rejected" to incoming emails from the entry loadbalancer. The rejection came from a health checking system on the node which took the out of service as it detected a fault with its ability to resolve DNS entries. The rejection was correctly issued, however, it was issued with the incorrect status code which ultimately lead to a rejection of the incoming message instead of a temporary rejection. We have corrected the behavior of the health checker across all nodes to issue a temporary rejection code instead of a permanent failure.
We are experiencing outbound delays, particularly in the EU zone. This significantly higher amount of deferrals (servers that are down, unreachable, deferring mail, i.e. experiencing similar network issues) creates a bottleneck.
We're currently optimizing and rerouting things to improve performance, things are moving but today will require some patience.
Comcast (AT&T) Business service SecureEdge is currently hijacking DNS requests, causing some users to receive HTTPS/HTTP errors when they click on links processed by ExchangeDefender. Unfortunately the Business SecureEdge is not a managed service so if it's enabled on your router/account you're going to run into issues. You can disable it from the Comcast Business web site but please read about the issues others are encountering in trying to turn this service off.
Call Comcast Business Support at (800)391-3000 and request to "remove Security Edge from my account and router/modem." Once the service is removed from your account, the errors and issues should go away.
Technical Details
Comcast is hijacking DNS lookups (this is done regardless of whether you use their DNS servers or public 8.8.8.8 or 1.1.1.1) and effectively blocking all lookups of the domain. Here is what a normal lookup for d.xdref.com looks like:
C:\>nslookup d.xdref.com 8.8.8.8
Server: dns.google
Address: 8.8.8.8
Non-authoritative answer:
Name: d.xdref.com
Address: 72.29.121.220
C:\>nslookup d.xdref.com
Server: UnKnown
Address: 192.168.1.50
Non-authoritative answer:
Name: d.xdref.com
Address: 72.29.121.220
Note that regardless of whether you use local or public DNS, the correct IP is returned as 72.29.121.220.
But if you have Comcast SecurityEdge, your request will be redirected:
C:\>nslookup d.xdref.com 8.8.8.8
Server: dns.google
Address: 8.8.8.8
Non-authoritative answer:
Name: d.xdref.com
Addresses: 2607:f740:e::16
2607:f740:e::ad
199.38.182.52
199.38.182.75
Note that even though we're using Google's public DNS in both scenarios, Comcast redirects those lookups to their blocking proxy. That you can't manage or control aside from disabling and removing it from your account. We hope this helps, it's not a service we encounter a lot.
We had a service issue from roughly 5PM EST - 5:35 PM EST. One of the internal logging facilities crashed and required manual intervention and adjustments to recover.
Our MFA/2FA features have been restored last year, apologies for a late update.
As a result of the upstream vendor not delivering on their SLA we've changed providers so expect MFA codes to arrive from new numbers. We encourage you to restore the MFA functionality as soon as possible (though preferably through authenticator apps which are far more secure and versatile than SMS).
12/03/2022 01:02 AM 20 days
We are still waiting for our service provider to complete their maintenance window.
If you are experiencing too many SMS drops, contact us via support.exchangedefender.com and request to have MFA disabled temporarily. Please be specific about which accounts you want it disabled on (provide login id).
12/01/2022 18:12 PM 21 days
Our outbound SMS services are being impaced by an upstream vendor maintenance:
Between 30th November 2022 05:00 (UTC) and 2nd December 2022 18:30 (UTC), AT&T will be performing a maintenance.
During the maintenance window, you may potentially experience MT, DLR and MO delays or failures for 10DLC SMS & MMS on AT&T US.
This issue has been mitigated and we have not had further reports since 8AM EST / 1 PM GMT.
To fully address all the potential issues that can cause the problem an update will be completed overnight. We will update the advisory after all the work has been completed.
10/05/2022 13:33 PM 18 days
We have received several reports from clients who were unable to login at admin.exchangedefender.com as Domain Admin or Service Providers. User login or service operation is not affected. We have rolled back our admin infrastructure to Tuesday (10/4/2022) version and service is back to normal.
We will update this advisory once the new codebase is in and we've been able to isolate the bug that is causing some administrators infinite 502 redirects.
ExchangeDefender & most of it's staff made it through the Hurricane Ian and it's level 1 hurricane winds. We're all good and safe, thanks to all who have expressed concern and thought about us during this difficult moment.
Those of you that visited our headquarters over the years have probably seen that our Lake Eola went up several feet and swallowed up the entire neighborhood. Most of our staff in the Orlando Metro area is without power/Internet but there has been no impact to our services. As a community we have a long weekend of cleanup ahead of us but we're so thankful this dangerous storm didn't cause more catastrophic damage.
We expect for everything to return to normal by Wednesday, October 5th. In the meantime, service levels will remain unaffected.
09/28/2022 16:59 PM 26 days
Hurricane Ian is expected to make landfall in Florida shortly and most of our staff is directly in it's path in the Central Florida region.
While we are prepared and don't expect any impact to our services, this storm is huge and will likely impact our staff. It will also catastrophically affect our clients across Florida and we're already assisting remotely.
We're asking our clients and partners for some patience with support SLAs and understanding as we wait for this storm to pass and support workloads to return to their normal levels. If you're in the path of the storm please stay safe.
We are currently working on an issue in our load balancing infrastructure; all services are expected to be restored by 9am.
Over the past week we've received several complaints from clients about M365 mail going to Junk Mail and in all instances the users did not deploy ExchangeDefender as required. After the domain is brought into compliance and properly rolled out (so there are no failures or warnings) the mail starts flowing normally again within a day or two (likely due to DNS caching).
We dedicated a good part of 2021 and 2022 requesting our clients comply with strict SPF/DKIM/DMARC rollout as it's being required by Microsoft, Google, and all other large email providers including ExchangeDefender. If you are experiencing issues please go to https://check.exchangedefender.com to run the DNS check and make the requested changes to your DNS. If you need help with your DNS we offer an affordable DNS service to manage and maintain your domain for you.
07/28/2022 14:53 PM 26 days
We have received two reports of Microsoft M365 domains protected by ExchangeDefender suddenly classifying large amounts of messages as High Confidence Phish. If you are running into this issue AND your tenant is correctly configured according to our rollout guide, please open a ticket with M365 and ask why the message is being categorized as such. Here are two things you should do:
1. Confirm that your tenant is properly configured and locked down to ExchangeDefender by following every step of this guide.
2. If all your settings are correct and Microsoft M365 is not helpful, follow this guide to turn off M365 phishing (which is likely causing this issue).
Nothing on the ExchangeDefender side has changed to cause this issue, and we are not able to replicate this issue with any of our managed clients or demo accounts on M365. Please confirm that all steps in #1 and #2 are correctly executed and applied, and if the problem persists ask Microsoft M365 to determine where the problem is. If our ranges are in the allow list AND we're bypassing their phishing/spoofing protection then please ask them how or why messages are getting quarantined by M365.
In the meantime, you can always rely on ExchangeDefender LiveArchive to access a live copy of your Inbox.
We received alerts regarding increased queue sizes and delivery delays from our inbound and outbound nodes. After investigating it was determined to be an issue with the logging server which logs incoming and outgoing emails for search and auditing. We are unable to tell when the delays begun, but most of the observed time stamps in the logs showed a 30 minute delay
service has been restored for all users
06/18/2022 13:58 PM 5 days
Most of the databases have mounted and service has been restored to those users. We're still finishing updates on the remaining databases.
06/18/2022 10:29 AM 5 days
We are currently working on restoring Exchange mailbox access from an active directory issue. We will update this NOC as more details become available.
ExchangeDefender has published the Follina Mitigation Advanced Feature and it is currently available to our managed and enterprise clients.
The policy is available under the Domain Admin login at https://admin.exchangedefender.com under Advanced Features.
When this policy is enabled, ExchangeDefender will consider every Microsoft Office attachment as potentially infected and will qurantine it on our network. From there, Domain Admin can follow the directions in the email to retrieve the message from our admin portal. If you have Advanced Features : Infected Attachments enabled, end users can also download these attachments on their own without help from IT/admin.
https://exchangedefender.com/images-documentation/advanced_features_follina_mitigation.png
Important: ExchangeDefender is already protecting all clients from the follina exploit in the wild through our antivirus. Please follow Microsoft's instructions.
Side note: This is not a good way to protect yourself and we're only publishing this due to an overwhelming demand by our larger clients. Microsoft's security record with Exchange and Office lately has made many IT people lose confidence in their ability to protect a Microsoft network. We will deliver a more elegant way of accessing prohibited attachments through the ExchangeDefender Sandbox soon, but we hope that this quick containmnent option is viable for clients that want to layer attachment policy blocking at the perimeter for the time being.
05/31/2022 16:14 PM 23 days
Updating the advisory to link to remote code execution proof of concept:
https://github.com/JohnHammond/msdt-follina
This RCE affects all versions of Microsoft Office, please follow Microsoft's official CVE.
ExchangeDefender is already finding and blocking these exploits through our antivirus security but we still recommend following Microsoft's advice to remove msdt associations.
05/31/2022 15:26 PM 23 days
Microsoft Office has an RCE exploit named "Follina" in the wild that can easily compromise a Windows PC even through a preview in Windows Explorer (.lnk and .rtf files). It affects all versions of Microsoft office from
To protect your clients please urgently turn off ms-msdt associations https://gist.github.com/wdormann/031962b9d388c90a518d2551be58ead7
If that is not an option, you can use ExchangeDefender to block the following attachments through the Domain Admin:
.xps
.pub
.ecf
.one
.mde
.mda
.doc
.dot
.wbk
.docx
.docm
.dotx
.docb
.wll
.wwl
.xlt
.xls
.xlsx
.xlm
.xltx
.xltm
.xlsb
.xla
.xlam
.xxl
.xlw
.ppt
.pot
.pps
.ppa
.ppam
.pptx
.pptm
.potx
.potm
.ppam
.ppsx
.ppsm
.sldx
.sldm
.pa
We are actively working on making Office attachment blocking a one-click setting and expect it to be published by the end of day 5/31/2022.
We've extended the functionality of one of the ExchangeDefender functions as a thanks to one of our largest and oldest service providers - you can now password reset an entire org and email the users their new credentials. You can access this screen by logging in as the Service Provider and selecting your Accounts > Activities > Security Reset.

Emailing of passwords around is a bad idea and a practice that's dated, so work is already underway to send the email via ExchangeDefender Encryption instead (but it being Monday morning we wanted to help quickly)
05/23/2022 14:12 PM 3 hrs
Monday Morning Update (10AM EST):
It was a relatively quiet weekend at ExchangeDefender, we haven't received reports of any new issues and everyone that reported a problem has already had the issue addressed. We're very pleased with the rollout and thank our partners that have been instrumental in getting their clients onboard with OAuth and MFA to help lock things down.
The biggest issue in the rollout so far has been with users that have never logged into ExchangeDefender and don't know their passwords. Here is what you can do to help them:
1) If you'd rather handle it for them remember there is a Service Provider function in place that allows you to mass reset login credentials for everyone in the org. You can pick your own password for them all (for emergency use only, not recommended) or create a randomized one to send to whoever manages the location (See https://www.exchangedefender.com/docs/sp for documentation; under SP login click on Accounts > Actions > Security Reset)
2) For DIYers: point them to the documentation on how to reset their password https://www.exchangedefender.com/docs/oauth or just a link straight to the password reset https://login.exchangedefender.com/ssp/reset-password
3) For power users: Deploy SPAM Manager and MFA with an oAuth app:
Mac OS X: admin.exchangedefender.com
https://admin.exchangedefender.com/apps/SpamManager/darwin/SpamManager.dmg
Windows: admin.exchangedefender.com
https://admin.exchangedefender.com/apps/SpamManager/win32/SpamManager.exe
05/20/2022 18:25 PM 3 days
Issue Reported:
ExchangeDefender users with Domain Administrator privileges are having issues logging in or unable to escalate privileges from the avatar dropdown.
Bug fixed at 2 PM EST / 18:00 PM GMT
The problem has been resolved. As usual, reboot or restart your browser session, confirm the issue isn't with local browser cookies/sessions/saved passwords by attempting your action in Incognito mode or a different browser.
05/19/2022 20:05 PM 3 days
Issue Reported:
When clicking on the "Click Here" link in the ExchangeDefender Quarantine Report, I get a "403 Forbidden":
Oops! An Error Occurred
The server returned a "403 Forbidden".
Something is broken. Please let us know what you were doing when this error occurred. We will fix it as soon as possible. Sorry for any inconvenience caused.
Bug Fixed @ 4PM:
The bug that caused this issue has been fixed.
If you experience this problem after 4 PM EST / 2:00 GMT please first check if you can replicate the issue in incognito mode or with a different browser on your PC.
05/19/2022 19:07 PM 3 days
Issue Reported:
Domain Admin / Service Provider login doesn't work at https://admin.exchangedefender.com. It redirects me and gives me an error.
Bug fixed at 3PM EST:
When you go to https://admin.exchangedefender.com you will be presented with a User login screen. To login as the Service Provider or Domain Administrator please click on the "Domain / Service Provider" button. If you still try to type in a domain name or service provider ID in the user login form you will be presented with the error "Invalid email address. If you are an admin please click on "Domain / Service Provider" button.
05/19/2022 19:02 PM 3 days
As of May 19, 2022 ExchangeDefender has completed implementation of OAuth authorization which will make logins and credential management more secure.
We will keep this post active to track any issues our clients experience. We don't anticipate many issues as the system has been running in production for over a year.
If you experience an issue, please first attempt to resolve it by opening your browser in an incognito mode and/or rebooting your device. Clear the cache. If the problem persists please open a ticket at https://support.exchangedefender.com with the following details:
1) Screenshot of the error
2) Login credentials
3) Any supporting info that may be relevant (is it an issue you get from SPAM report? attach .msg of it or provide the URL you clicked; browser errors? provide info from https://whoami.exchangedefender.com)
Customers who have not followed step 10 of the deployment guide for Office 365 + ExchangeDefender are likely to see delays for incoming emails as Microsoft is throttling deliveries from new nodes in our LA data center. If you are seeing delays, please make sure you have exception policies created for both of our delivery ranges 65.99.255.0/24 and 206.125.40.0/24
The issue has been resolved. Any past due quarantine report (scheduled between 4PM Eastern until 630PM Eastern) will not be regenerated, but the next scheduled report will arrive.
05/12/2022 21:57 PM 10 days
ExchangeDefender quarantine reports are currently paused while we investigate performance issues
One of the two local outgoing SMTP servers went offline, but Exchange kept preferring the down server. The downed server was removed from the smart host list and mail was instantly routed via the working outbound node.
05/03/2022 13:28 PM 20 days
We are working on an issue that is affecting outbound mail from some servers. You may receive this notice with the subject "Delivery delayed". We are working on it and expect to resolve the issue shortly, there is no need to resend the message.
This message hasn't been delivered yet. Delivery will continue to be attempted.
The server will keep trying to deliver this message for the next 1 days, 19 hours and 51 minutes. You'll be notified if the message can't be delivered by that time.
We have received several tickets regarding an expired certificate for ExchangeDefender legacy endpoints (darkwing.exchangedefender.com, rockerduck.exchangedefender.com, etc). If you are still seeing these errors it's likely because your IT guy has been asleep for years and hasn't updated DNS records that have been phased out from production in early 2020.
Please follow the following guide to setup your DNS correctly: https://www.exchangedefender.com/docs/exchange-setup
tl;dr; Make sure your OWA bookmark is at https://owa.xd.email/owa and that your autodiscover cname is pointed to autodiscover.xd.email. If you do not have the technical resources in house to make DNS changes/etc, please contact us at https://www.exchangedefender.com/help and we'll do our best to assist.
Recent world events and sanctions also impact network service providers (ISPs, fiber providers) and in the interconnected world this simply means: less reliable Internet for the next few days.
Major Internet backbone providers are leaving Russia and stopping routing for the .ru tld, and similar actions will be required of other western backbone providers. If you experience connectivity or performance issues for the next few days, we recommend checking Downdetector or ThousandEyes first to see if there are network issues affecting global backbone service or your local Internet service provider.
Of course ExchangeDefender staff will be happy to assist you with any issues you may encounter. If you need to open a support request regarding performance, connectivity or network event please include the following information in your ticket:
1. Local ISP
2. IP Address from the client site experiencing an issue. (can be obtained from our whois service)
3. Traceroute output to the following routers: 65.99.255.1, 72.249.180.1, 206.125.40.1 (Start > cmd > tracert 65.99.255.1)
This information helps us understand where the problem is being experienced and allows us to properly escalate/report a routing problem to the backbone provider.
Due to a configuration issue one of our networks relayed marketing (bulk) mail this morning, February 21, 2022. Because ExchangeDefender Exchange services are not designed for mass mailing, there is a possibility that our range might end up on an RBL.
We have removed the affected IP addresses from our outbound routing and do not forsee any issues. However, some RBL providers react by blacklisting an entire range or AS upstream provider range. There is no need to open a ticket if you run into the RBL issue, all our IP addresses are monitored in realtime across hundreds of RBLs and we will work on delisting them should they become published anywhere. If your users run into an issue sending mail, please remind them that ExchangeDefender Email Bypass is available to all Pro subscribers and that infrastructure is capable of bypassing most RBL/ISP blocking so definitely check it out.
Microsoft has provided additional information regarding the issue here.
If you would like our assistance with this problem please let us know, we've been helping clients with this issue all weeekend (standard consulting rates apply unless it's an emergency).
01/02/2022 01:52 AM 21 days
If you're running an on-premise Exchange 2013 or newer, your mail flow may have suddenly and inexplicably stopped. Please follow the link for more information about this Microsoft-related issue (in order to restore your mail flow you need to disable Exchange malware checking which is a potential security risk)
Until you take account of the situation and determine your security impact, remember all ExchangeDefender Pro clients get LiveArchive which will allow you to continue working.
As a matter of policy we do not comment on security events that are not related to our infrastructure. However, considering the significant PR that the Apache Log4J CVE is rightfully getting, we have received multiple inquiries so:
ExchangeDefender does not use Java on any production systems.
ExchangeDefender NOC uses one Java-based solution on our internal network, however, it does not rely on Log4J so it is not impacted by this CVE.
We do not expect any impact to our operations. However, significant effort has been put in by our teams since this vulnerability has been announced and we've taken significant precautionary mesaures (such as mapping and blocking IP addresses that are scanning systems for this vulnerability and attempting to exploit it) to help secure our clients from other emerging threats likely to come from the same sources.
Overall delivery and livearchive delivery have stabilized and all services are operational.
11/08/2021 15:23 PM 15 days
All services have been restored ~8 AM and performing well for about 1:30hr at this point.
We are still working on delivering all the mail to LiveArchive, as well as misc other maintenance items that we're required to perform after every performance issue.
11/08/2021 12:55 PM 15 days
Mail is again flowing normally and delivering mail that was delivered to ExchangeDefender. The delivery process should be completed by 8AM.
We are continuing to work on this issue and will provide more details.
11/08/2021 12:17 PM 15 days
We are currently experiencing a very high load processing inbound mail, which is causing delays in delivery.
On Friday 10/22/21 at 8AM our current certificate will expire for our Hosted Exchange platform. Our attempts to renew the certificate with our vendor have failed and after multiple escalations, it was determined that our type of certificate is no longer issued by our current vendor. Every organization in our Hosted Exchange has their own certificate and key pair used to serve their OWA and Outlook instance to maintain best security practices.
We are continuing discussions with them in attempts to renew the certificate and preserve the current implementation with regards to maintaining a unique key pair for each organization.
In the unlikely event that we are unable to continue our relationship with our current vendor we have a backup plan in place to replace the certificates which will occur on Thursday evening from 11PM, through Friday morning at 1AM. If we have to execute the backup plan, services may be temporarily interrupted as we perform the request and swap of the certificates.
The networking issue related to the timeouts has been solved, clients are reporting no issues connecting at this time.
10/11/2021 13:23 PM 12 days
We are investigating reports of timeouts when making the initial connection to https://admin.exchangedefender.com
Access has been restored
09/30/2021 14:06 PM 24 days
We're currently working on an issue affecting Exchange 2016 service manager as well as ExchangeDefender SMTP logs. Actions dispatched to service manager will be queued and replayed once service has been restored.
UCE has added RBL listing with a superset of network we use for relaying outgoing emails sent by ExchangeDefender customers. The RBL listing is classified as an ISP block, which generally will take out the entire assigned netblock. In this case, the block is against one of our data centers netblocks which includes the outbound network we use in Dallas (174.136.31.16/28)
The block should automatically remove itself. We will continue to monitor the listing and its impact.
All mail has successfully flushed from the queues
06/28/2021 07:47 AM 26 days
We've received reports from a couple customers regarding mail delivery delays occurring with some outbound emails. Upon further investigation, one of the edge nodes had an outdated smart host configuration, using a node that was decommissioned over the weekend. After successfully resyncing the configuration we observed outbound mail flowing on the affected node.
Beginning at 1:00PM Eastern quarantine reports resumed their normal service. Previous daily and intradaily reports were going out at the incorrect time due to a legacy timezone conversion. We've successfully replaced the legacy logic with an up to date method to accurately convert the time to the users requested time and time zone. Going forward, users in time zones that do not observe DST will no longer have to adjust their quarantine report times when our servers switch to and from DST
06/09/2021 19:23 PM 13 days
As of noon EST, we are seeing Quarantine Email reports generation and delivery returning to normal. We are continuing to work on this issue.
In the meantime, please keep going to https://admin.exchangedefender.com to stay on top of all of your SPAM quarantine messages.
06/08/2021 12:37 PM 15 days
We have been investigating multiple reports of ExchangeDefender Quarantine SPAM reports not reaching their intended target. Unfortunately due to the contents of Quarantine Reports (spam message subjects, senders, etc) they tend to get caught by SPAM filters and are a legacy service of ExchangeDefender Pro. We're working on it.
In the meantime, please go to https://admin.exchangedefender.com. It will give you realtime access to all your queued up junk mail and you'll be able to read it in a secure browser, reply, forward, print and in general be done with your SPAM reports in a fraction of the time. If you're an IT provider, please forward this documentation to your client as well, it will walk them through the whole process and explain all the features: https://www.exchangedefender.com/docs/user
We will be performing maintenance in our Dallas data center from Friday evening until Sunday.
Throughout our maintenance period we will be taking ExchangeDefender web UI services offline for brief periods, however, mail should continue to flow without interruption.
There will be a brief interruption of service across all platforms starting on Saturday 12:00 AM Eastern and is anticipated to last up to 15 minutes.
Friday evening from 8PM Eastern until Saturday morning we will be performing maintenance in our primary data center. There will be periods where some services go offline as we switch things around, but we anticipate having each service back online within 10-20 minutes. Mail flow should remain uninterrupted during our maintenance period.
For the past day or so we have been getting errors on delivery to Microsoft properties (hotmail*, M365*, etc) with various error messages:
"Not authorized to relay messages through the server that reported this error"
"This message has not yet been delivered. Microsoft Exchange will continue to try delivering the message on your behalf. "
We have removed the IP addresses that Microsoft is no longer processing and we are working with them on determining what the issue is - the IP addresses are not on any RBLs so there is nothing more we are able to do other than to not deliver mail to Microsoft from IP addresses they are rejecting mail from.
As a result of these changes, there should be no issue after 9:30 AM EST today. We will update this ticket once we get more information from Microsoft.
As of 11 AM EST, all outbound services are reporting green.
There is a delay in inter-domain (ExchangeDefender-to-ExchangeDefender client emails, does not affect Exchange) mail delivery and we are confident that will be sorted out shortly.
04/13/2021 14:39 PM 10 days
Work is still ongoing with outbound-auth and outbound-xdgrid.
We were also made aware of bounces from M365 clients that use our smarthosts. The issue that caused that problem has been resolved, if your message bounced (if you received an error similar to below) please resend it.
Your message couldn't be delivered to the recipients shown below. Office 365 Multiple recipients Sender Action Required Sender not authorized for relay Couldn't deliver the message to the following recipients: How to Fix It When Office 365 tried to send your message to the next server outside Office 365, that server reported an error that it couldn't relay your message. It's likely that the email server isn't correctly set up to receive and relay messages from your organization. To fix this issue, forward this non-delivery report (NDR) to your email admin. Was this helpful? Send feedback to Microsoft. More Info for Email Admins Status code: 550 5.7.367 The sender's message was routed to an email server outside Office 365 that returned an error that it can't relay the message. It's likely that the server isn't set up correctly to receive and relay messages sent from yourdomain.com or from youruser.
04/13/2021 13:28 PM 10 days
DNS problems have been addressed and outbound mail flow has returned to normal across all data centers.
We are still addressing an issue with outbound-auth (used by IoT) and outbound-grid (used for Yahoo/BT/freemail system retries when they sporradicaly have issues) where performance is still degregated.
04/13/2021 11:22 AM 10 days
We are currently experiencing reduced performance across our ExchangeDefender outbound networks. The issue is DNS related and we're making adjustments to network resources to help improve performance.
As of 2:30 PM EST the IP address has been removed from SpamCop. We will not resume routing mail through it for the time being (many email operations cache DNS lookups, particularly from dangerous sites)
04/05/2021 18:09 PM 18 days
One of the IP addresses in our outbound grid (174.136.31.22) has been listed in SpamCop RBL.. This is rather unusual for a number of reasons, but the IP address delisting has been completed. The IP address was removed from the rotation so it doesn't inconvenience the existing clients (as many places have SpamCop listed IP addresses set to bounce).
We are still investigating the original issue that caused the listing.
ExchangeDefender LiveArchive maintenance has been completed. If you received any error/bounce/notice messages about delays/deliveries, rest assured the messages have been delivered and the message was issued as a notice only (while messages were in queue for any node/service that was under maintenance at any given time).
We have also completed the rollout of OAuth on LiveArchive, bringing the admin, livearchive, encryption, and web file sharing under one single sign on roof (for use with Google Authenticator, Microsoft Authenticator and any open oAuth agent) for a simplified more secure login experience.
03/25/2021 13:37 PM 29 days
We are in process of making capacity and performance adjustments for LiveArchive.
One of the DNS adjustments caused a series of rejections around 9AM EST:
The original message was received at Thu, 25 Mar 2021 07:00:42 -0400 from outbound1.exchangedefender.com [65.99.255.232]
----- The following addresses had permanent fatal errors ----- <123xyz@outbound.livearchive.exchangedefender.com>
(reason: 550 Host unknown)
----- Transcript of session follows -----
550 5.1.2 <123xyz@outbound.livearchive.exchangedefender.com>... Host unknown (Name server: outbound.livearchive.exchangedefender.com: host not found)
The extended TLD and reputation services have been addressed and we're comfortable closing this incident having fixed the problem.
The original issue has caused us to have series of meetings regarding priorities in ExchangeDefender security suite, given that the recent exploits are in line with the Microsoft hack. Between nearly every Microsoft Exchange server in the wild compromised by the HAFNIUM exploit, and the extent of SolarWinds hack, a more personal service is needed.
If you were affected by this hack and are our partner, we are able to assist you in cleaning it out as well.
03/03/2021 18:42 PM 19 days
ExchangeDefender has removed IP reputation services for extended/vanity TLDs and the entire network is back to normal.
We will be replacing the protection for these top level domains with an ExchangeDefender solution. allowing you to accept/block on a tld level. Outside of the general TLDs (.com, .net, .org, .mil, country code tlds), you're looking at having to deal with over 1,200 top level domains (like .cam, .casa) and an unlimited number of domain names that can be registered through their NICs, some with absolutely 0 tracking or policing. In short, you should just basket-ban them and only whitelist specific domains (estoyenmi.casa) that you trust. More details on the management and what went wrong tonight.
03/03/2021 17:23 PM 20 days
We have removed extended tld reputation services from the edge of our network, and the change has cleared development and testing. Currently the update is propagating through our entire inbound network (allow additional 15-45 minutes for propagation).
While ExchangeDefender will no longer reject vanity/extended TLD messages or hostnames, it is still possible that messages from those sources contain SPAM and malware. If we detect dangerous content, we will categorize messages as SPAM and route it according to your domain policy.
This event will be receiving further updates over the next few days, please stay tuned.
03/03/2021 15:50 PM 20 days
ExchangeDefender is currently having issues processing mail from extended / vanity top level domains (ex: .aero, .xxx, .moscow). Senders are receiving an error:
5.5.0 5.5.3 Your mail provider suffers of poor reputation. Please contact them ID8841086
Messages from these servers and addresses will start processing again shortly.
Background: Extended tlds are a constant source of malware and attacks on our network. The provider that we are receiving registration data from (to see if the domain is newly registered and thus banned vs. reputation checking) is providing bad data, causing the rejections. We are currently working around it.
We are currently actively updating all Exchange servers in our cluster in response to the HAFNIUM zero day exploits. A small subset of users (13%) experienced the inability to access their mailboxes from 2am-3am EST (due to the inability to cascade their updates in a timely manner), however, all other customers will see no impact from the patching. As servers are patched they are removed from mail flow and all active connections are offloaded to a fully patched server. All unpatched servers have been removed from the load balancing proxy in order to mitigate the ability for the aforementioned exploits to be utilized. Prior to patching, we ran all available detection scripts against all nodes and have confirmed none of nodes have been exploited. We will continue to monitor advisories from all our vendors and treat all HAFNUM related updates as critical.
While we have marked this issue as resolved we wanted to offer further updates (after banning M365 misconfigured instances from ExchangeDefender - they will still arrive in your SureSPAM folder and if you whitelist the domain they will pass on as normal)
We will have a new managed offering launching later in Summer 2021 to address these but for the moment we are dealing with multiple attack vectors and appreciate every .eml report we can get at https://support.ownwebnow.com
02/24/2021 00:49 AM 30 days
As mentioned in the previous update, we have been blocking a lot of the new exploited IP addresses. One thing they all seem to have in common is that they are abusing organizations that match these two criteria:
You will see these headers in many SPAM pieces.
X-MS-Exchange-Organization-MessageDirectionality: Incoming
X-MS-PublicTrafficType: Email
X-MS-Exchange-Organization-AuthSource:
ME3AUS01FT006.eop-AUS01.prod.protection.outlook.com
X-MS-Exchange-Organization-AuthAs: Anonymous
For the time being, we will classify Microsoft email from these open relays as SPAM far more aggressively. It will not impact normal traffic from Microsoft, but if they are an open relay those messages.
02/23/2021 17:13 PM 24 min
We have been monitoring an explosion of new compromised systems that are suddenly broadcasting large amounts of SPAM. These IP addresses have never been used for SPAM activity before (and clearly belong to legitimate companies) and we are blocking them as fast as they show up on our firewalls. Here are some of the top subjects:
Restore Your Gut Health As You Sleep with Peptiva
go-peakbusinessfinancing.com $COMPANY // Reach the Peak
Green Veggie INFLAMES Diabetes Type 2 (Avoid)
Worried about your identity? Try ?ife?ock free!
African Priest Helps White Man Gain 6 Inches
White Man Offers Wife To African Priest For Member Growth Secret
2021 is Here - Big D Paving Co Start of Year Funding Deals
While most of these are getting picked off by our SPAM filtering natively, we are actively mapping out this new botnet and blocking it aggressively.
If you have users with SureSPAM policy set to "Deliver" you should immediately change it to Quarantine/Store so your users aren't being annoyed with pieces that are coming from IP addresses with good IP reputation.
We have made adjustments on the outbound network and everything is moving along smoothly. All queued mail has been dispatched and your users may have received a delay notification for the email, but rest assured it has been delivered.
It appears during an automated failover to the backup EDGE servers a looping condition was introduced and both primary and secondary EDGE servers began to cycle mail between each other instead of to the outgoing destination. I've corrected the routing logic on the secondary servers and resolved the quorum issue which originally led to the secondary servers becoming active. From this point on, all edge servers will work in an active/active setup to avoid future inconsistencies between active/backup logic.
02/16/2021 16:38 PM 7 days
We are currently experiencing delays on our outbound nodes.
Our engineers are working on a solution at the moment, please rest assured we are working diligently to restore performance back to normal.
Thank you for your patience.
On 1/7/21 At 22:00 EST we will be performing an update to our core router which will require a reboot. Services are expected to be offline for 15 minutes, until 22:15 EST
All work on LiveArchive has been completed in 2020, we're looking forward to keeping you online when mail or your mailbox go down in 2021 and beyond.
12/30/2020 20:53 PM 23 days
Bulk of the storage/allocation work has been completed as of 4PM EST. We will continue with additional work but we do not expect errors displayed to anyone, so if you get one please let us know at https://support.exchangedefender.com
12/30/2020 13:57 PM 24 days
We are conducting maintenance on our LiveArchive clusters December 30-31, there will be sporradic latency / timeouts / outages as we make adjustments and upgrades. While the specific cluster your mailbox resides on is under maintenance you may receive an Error notice, give it a minute or two and refresh.
We have been receiving phone calls all day about the implications of a widely reported SolarWinds compromise that has so far hacked the US government & Microsoft:
https://blogs.microsoft.com/on-the-issues/2020/12/17/cyberattacks-cybersecurity-solarwinds-fireeye/
We have never used SolarWinds on our network, and our Microsoft-connected resources are not affected. As always, it's prudent to have a credential-reset schedule strategy and to enable 2FA/OTP on every resource available.
Access has been restored to Exchange
12/16/2020 08:17 AM 7 days
Our monitoring has detected down access to Exchange starting at 3:13 AM Eastern. Our engineers are working on diagnosing the issue
After speaking with O365 support we've learned about a new connection filtering policy in test. In order to override the default connection limits, you must override the default policy depending on your mail flow volume
10/01/2020 17:17 PM 22 days
Customers on O365 will have to raise a case with Microsoft detailing the following error rejection codes
Microsoft has started to throttle deliveries from ExchangeDefender with no rhyme or reason. We've opened up a case with Microsoft, but we urge partners to do the same.
10/01/2020 16:56 PM 22 days
We are again seeing random delivery failures and server busy errors while delivering mail to Office365. It appears to be affecting multiple clients.
The issue has been reported to Microsoft and we hope they sort it out quicky (The error they are reporting is (Deferred: 451 4.7.500 Server busy. Please try again later from [65.99.255.116]. (S77719) [CO1NAM04FT)
In the meantime, this is why you have LiveArchive - you can continue to send and receive mail and access all the inbound mail that may be backed up. You can access LiveArchive at https://livearchive.exchangedefender.com
We have seen slower processing times on two of our clusters in Los Angeles, inbound13 and inbound16 starting this morning around 9-9:15AM. Our standard diagnostics did not turn up any obvious issues so these systems have been pulled from production so that investigation can continue without delaying mail delivery.
We have removed those clusters from inbound mail routing and have moved all messages to another cluster to process. We expect that all the messages from i13 and i16 will be processed and delivered in the next 5-10 minutes (11:10-11:15 AM EST).
The issue with Outlook Web Access has also been addressed now.
We will continue to monitor and review the perfromance but we have confirmed that all services are functional and there are no accounts reporting errors or login timeouts.
08/24/2020 11:36 AM 30 days
The issue regarding mail flow has been addressed, all mail that has been accepted/delayed since approximately midnight (when the issue started) has been dequeued from ExchangeDefender and delivered to Exchange.
We are still working on the other reported issue related to Outlook Web Access logins. Please use LiveArchive (https://webmail.livearchive.us/) for the moment.
08/24/2020 11:07 AM 30 days
We are investigating reported errors in email delivery and OWA login that started earlier this morning. We will keep this post up to date as services are recovered back to normal.
Between 4:10PM and 5:01 PM we noticed delivery delays to and from Exchange 2016. Upon investigation, the delivery delays occurred at the Edge network which is responsible for message coming into or leaving Exchange. At 5:01 PM we were able to rectify the issue and begun to process queued messages.
A subset of outgoing messages may have responded with "host not found" between 11:30AM and 11:32AM
While developing new changes on an outbound node, we noticed the load balancer did not pull the testing server out of rotation and temporarily allowed mail to relay through to the test server. Unfortunately, the outbound test node wasn't fully configured to handle routing from customers and responded with the following error
DSN: Host unknown (Name server: 127.0.0.1: host not found)
The test node was quickly removed from the network and we confirmed it was no longer in rotation before continuing development.
At approximately 11AM EST, one of the ExchangeDefender outbound network endpoints (outbound3.exchangedefender.com) was brought into rotation without all the relay ACLs authorized. The result is the message below for some clients/domains whose policies did not load properly. The error they received is a 500 Relaying Denied, and it's been fixed/addressed.
Your message wasn't delivered due to a permission or security issue. It may have been rejected by a moderator, the address may only accept e-mail from certain senders, or another restriction may be preventing delivery.
The following organization rejected your message: outbound3.exchangedefender.com.
If you received this error message, please go to your Sent Items and resend the message.
The issue with Exchange has been addressed. We started a major project last Thursday involving the entire Exchange team to address series of expoits that have been documented in the wild and could pose threat: https://swarm.ptsecurity.com/attacking-ms-exchange-web-interfaces/
The actual issue that caused a problem was unrelated, in one piece of infrastructure suddenly failing Microsoft Health checks for proxying requests to the backend. While this was resolved quickly, diagnosing it took a while. All users had access to ExchangeDefender LiveArchive during the work and all services are back to normal.
07/27/2020 13:58 PM 27 days
The issue with OWA/EWS has been addressed, and all users that were on the impacted are now reporting connectivity and routing is back to normal.
07/27/2020 13:38 PM 27 days
Some users reported they are having issues connecting to OWA and Outlook. We are investigating what could be causing the issue, please stand by.
We'll update this SA as soon as we have more information.
Thank you for your patience.
Microsoft's latest update to Microsoft Outlook is causing issues on some workstations. Essentially, Outlook starts up and crashes immediately, and running it in safe mode or in an isolated/compatibility mode doesn't fix it (as it did in the past when this issue happened).
The only thing you can do if you experience this issue is to roll back the Microsoft update to the previous release. To do so, run a version of this command with paths appropriate to the way your workstation is configured.
"C:\Program Files\Common Files\microsoft shared\ClickToRun\OfficeC2RClient.exe" /update user updatetoversion=16.0.12827.20470
For more information, and further troubleshooting in the wild, take a look at the following reddit thread:
https://www.reddit.com/r/sysadmin/comments/hrq0mn/outlook_immediately_crashing_on_open_after/
This is a software issue with Microsoft and is not something under ExchangeDefender's control or ability to assist/fix, until Microsoft gets this repaired we are recommending either rolling Outlook back a version or using our LiveArchive or Outlook Web Access from your browser or mobile device.
We are getting reports of rejections on the outbound SMTP. The rejections are due to a DNS failure (reverse DNS lookup / PTR) on one of the ranges we use to proxy deliver email. As of 6:11 AM this issue is resolved and mail is moving without error. If you got the NDR, please resend the message and it willl go through normal delivery process bypassing the affected range.
We have resolved all the issues and completed all migrations and cleanup. Everyone is now on the new tech and everything is working correctly.
If you moved away from ExchangeDefender and still need some data, it will be live for another 60 days on our legacy platform, here are retrieval instructions.
If you would like our assistance, please let us or your IT provider know.
06/19/2020 20:43 PM 3 days
We wanted to offer one final update before we close the ExchangeDefender NOC covering our Exchange migration.
The past few days have been largely consumed with cleanup and misc configuration requests already covered here. By far the biggest issue has been reseeding and legacy copies of mailboxes exceeding 25GB using nearly all internal, Microsoft/powershell, and third party tools there seems to be no predictable, foolproof, failsafe way to migrate a mailbox. The larger mailbox gets, the more difficult it seems to port (one particular user has been waiting on their mail for 2 weeks - they have a 70 GB mailbox and it's taken dozens of attempts of repair/recheck/export/move/seed/verify) and it has been the greatest source of frustration for us and for our clients, largely because the progress indicators are unreliable and process very prone to failure the larger the mailbox gets. This is why when we started offering 2016 years ago we set up the 50GB quota with 15GB realtime and 35GB in place archive setup so we can deliver on both service restoration and disaster recovery.
We are continuing to assist our partners in the following areas:
At this point everyone can connect, mail delivery and legacy reseeding are in progress, all systems for Exchange, ExchangeDefender, and
LiveArchive are working normally.
We're looking forward to closing this ugly chapter. We have done everything in our power, and we couldn't be more thankful for our partners who have helped us with the cleanup of the Microsoft disaster. Thank you. We are sorry that so many clients were inconvenienced with this, we planned and managed every step of this migration by the book with thousands of other successful migrations that happened from 2016 Aug 2019, but when your vendor pulls the rug underneath you and damages hundreds of mailboxes unannounced many of us will soon be enjoying the first day off in June. The only good news is, you will not have to go through this process again.
06/16/2020 19:18 PM 6 days
We wanted to offer a major update on the migration, specifically covering the major issues we have addressed for some clients during the cleanup phase.
Distribution groups, forwarding - We have received reports from several organizations regarding issues covering distribution groups, group members, forwarding account directions (forward vs. store & forward). If any objects failed to import due to configuration/contents/policy/etc it is in the retry queue and will be published shortly.
Add / Delete Mailbox - We have addressed a bug in the add/remove process that was prohibiting certain organizations to add/remove accounts. Originally, as noted on anythingdown.com NOC, we blocked this function entirely because users were looking at an empty list and creating mailboxes (that would cause a collision when the new mailbox was migrated from the source). This problem is fixed, if you encounter an issue please open a ticket with a screenshot and as much info as you can provide.
Add / Delete Organization/Domain - At this moment it is not possible to add/remove organizations, or those that were in the system recently. In order to finalize the migration, the routing policies are locked down (meaning if you deleted a domain, ExchangeDefender will still treat them as local). We look forward to wrapping this up shortly.
Password / Login issues - This is by far the biggest ticket group category, we are still processing double digit requests for credentials, credential resets, and credential tests. Similar to the next group:
Outlook issues - We are still spending a lot of time going through the basic Outlook configuration steps. For an overwhelming majority, this transition has been transparent. Those that did not and had to take a manual configuration route, the process has been described at anythingdown.com 1) Make sure you have an autodiscover record 2) Make sure it propagates, then run the autodiscoverregistryhacks.zip 3) If you don't control your DNS, make adjustments to your local systems hosts file 4) Setup Outlook with autodiscover, the UPN must be used as your login address if you've changed it from your primary SMTP address.
Missing & Syncing Emails - Every mailbox that has been reconnected has either had all it's mail delivered directly, delivered in a Catchall account - user@domain.com. Some users are confusing items they see in their Inbox in LiveArchive but not in their Outlook/OWA (but after extensive searching we keep on finding missing messages in folders, Deleted Items, etc). If something is missing and absolutely critical in LiveArchive just click on the message and click Forward to your email address and the message will be forwarded to your Outlook/OWA.
Store & Forward - Several users were also unfortunately caught up in a custom policy that did not get migrated to the new Exchange. These are more legacy configs we did for some users in AUDC, things like renaming the OU or primary domains. For some of those accounts, the store and forward rule because a forwarding only rule, skipping the Inbox and going straight to the person that it's being copied to. We have fixed this issue and it should not be happening again.
Autodiscover - We have gotten several complaints about autodiscover. Microsoft has removed manual configurations in 2013 and no modern version of Microsoft Exchange supports a manual server setup. However, this is something that could be easily rectified even with minimal technical skills by modifying the local hosts file if you don't have the credentials to do it properly by modifying the DNS. Absolutely everything in the new infrastructure relies on the autodiscover record!
iPhone / Android Setup - For the most part, we are just confirming that all mobile devices should work fine with owa.xd.email as the server name, ditto for EWS integrated applications, we have not received more than an inquiry for the server name. For Android, things get sketchier when you consider all the different vendors, apps, and configurations. Again, so long as autodiscover is present and configured properly and your device is using a modern client, it should just work. When it doesn't, recreating it takes a few minutes.
NDR - Non delivery receipts and errors are always of high interest to our NOC team as we continue to go through cleanup and audit all the tickets and users.
These are the issues we are currently working on, in 3 shifts, and sorting them all out as fast as possible. I know that for many of our clients this transition has been messy, but you are on such a better and more secure platform that won't require you go through this process again. While modern platforms are more secure, their recovery from a disaster or issue (as some of you unfortunately went through) is extensive and at times unpredictably slow - so you have this much of a committment for us, we will make sure LiveArchive is able to step in on a whole new level when things like this happen.
06/16/2020 07:53 AM 7 days
We're in the final stretches of importing public folder data from the SCROOGE, LOUIE and GLADSTONE cluster. Folders from DARKWING were successfully imported. Public folders from ROCKERDUCK will be exported in the next batch along with public folders with more than 5000 items.
06/15/2020 10:11 AM 8 days
We are near finished with completing the first batch of data imports for public folders. We will be remapping identities and public folder permissions once the import completes (estimated around 730-8AM Eastern). We are targeting making the first batch available by 10AM Eastern
06/15/2020 06:04 AM 8 days
Public Folder Update
We're in the progress of migrating public folder data. We fully intend on restoring all public folders with less than 2000 items by the start of business on Monday June 15th. However, we are not imposing the item limit to aptly named company calendar and contacts folders. Unfortunately there are a lot of public folders that were previously renamed in Outlook (on the legacy clusters) which is making remapping of the new identities difficult.
Public folders with more than 2000 items will be imported after the initial batch import completes.
Public folders will automatically become visible as additional mailboxes in Outlook and can be mapped in OWA by adding the public folder to the favorites. Public folders will be renamed by prefixing the org to the public folder name, removing the MSP name and the customer domain. For example, the previous public folder "demodomain.com_public" for the org demo will become "demo_public". We understand renaming the public folders may require some minor changes in LOB software, however, the renaming is required to ensure uniqueness of the public folder name.
Partners should expect to see public folder permission management inside of service manager by the end of the week.
We are taking requests to prioritize public folder imports. If your customer does not see their public folder by the start of business, please open a support request titled "Public Folder: expedite" . Inside the service request we will require the domain name of the customer requiring public folder data. If you happen to know the name of the specific public folders to expedite, they will be accommodated in the request. Customers with more than 2000 items requesting expedited access to public folders will have their expedited request filtered to mail within the last 90 days and the rest of their data will be imported in a subsequent batch.
06/10/2020 15:45 PM 13 days
11 AM Update
Mailbox Data Reseeding
At 10PM last night we picked up the pace of email delivery for users whose automated Exchange migration failed. If you had a user in that situation for days, we have created an empty mailbox for them so they can start working, and their old mailbox is being imported in the background. Within a day, it will look exactly the same as the old thing except much faster, safer, more secure, and on the new generation of Exchange.
Account Connections
We are still assisting clients with password resets, account reconnections, misc Outlook issues and mobile. At this time there is nothing else to report on this front as all the issues are addressed following the instructions already mentioned in this NOC advisory. Outlook, mobile, OWA, EWS, printer/CRM connections, everything works. This is by no means a new system for us, remember that we started offering Exchange 2016 in 2016 and have been facilitating migrations to it ever since. While the disaster has been in the migration failure for so many, the experience on the new platform is not raising any issues. We're even slightly hopeful because many of the reported issues clients had in Exchange legacy (connectivity, timeouts, email delays, etc) have not been a problem on the next generation so far.
Next Steps
We will likely spend bulk of Wednesday and early Thursday completing mailbox reseeding, redelivery of mail from 6/1 - 6/9, and getting everyone connected. Thankfully LiveArchive has been a life saver and people have been able to work from there, we want to make sure everyone is back in their Outlook, OWA, mobile experience and we can move forward.
Public Folder data sync and reconnection will happen closer to the weekend, at this time we do not have a firm time frame but the process has been scripted, tested, and certified for months so we do not expect issues there.
We will keep you up to date here but PLEASE if you still are not able to get into your Outlook Web Access at https://owa.xd.email/owa open a ticket with our team and we'll help you get reconnected and going.
06/10/2020 03:07 AM 13 days
11 PM Update
We are starting to replay more mailboxes faster and get everything in sync.
At this point the next stage of migration recovery is largely automated and one-on-one for weird Outlook/Sync problems. We will not have further updates from the migration team on this ticket until 11AM.
06/09/2020 18:28 PM 14 days
We are still working on password resets, last week mail sync, and old mailbox sync for those that failed Microsoft's automated migration.
If you are at this point not able to get into Outlook Web Access, please open a ticket and list which email addresses that are not able to login to OWA (one per org)
06/09/2020 07:40 AM 14 days
3:30AM
We are still wrapping up tickets from the day, a rather busy Monday getting everyone sorted out with Outlook cleanup and resync as required.
If you encounter any problems and are updating tickets, PLEASE provide screenshots and/or detailed error/log reports if you possibly can. Our support front line typically collects the information, double checks it, passes it on back to NOC or network admin on duty for resolution. If the error is vague the wait time and delay can depend on how long it takes support to actually determine the issue. So for example, if you're having login problems please specify your credentials and the site along with the error that you get. If you are getting mail delivery errors, post the NDR (non delivery receipt) or anything that will help us get your account and issue sorted out faster.
06/08/2020 23:36 PM 14 days
7:35 PM
We are still replaying last weeks email into all affected mailboxes. You will see a "CatchAll-Import user@domain" folder with messages that were delivered before your mailbox could successfully go online.
06/08/2020 23:13 PM 14 days
Monday
Overall, things are going in the right direction and we're going through typical Outlook cleanup, some reseeding, etc.
We have spent the day resetting passwords and helping clients reconnect their Microsoft Outlook, etc. Here is what we're seeing and hearing:
1. Many accounts need password resets. About half the work we've done today in support has been a simple password reset, so if your account is not letting you in with credentials you know, please reset it and give it 5 minutes to sync up. If that doesn't work, open a ticket immediately with the email address as the subject. If your mailbox is stuck in the password reset request, likewise, open a ticket.
2. Questions about Exchange autodiscover. No, you do not need to change your autodiscover if you've already got one. Yes, you absolutely need to have an autodiscover record for 2016 and above there is no "server name" because Outlook will not resolve it for configuration (it's outlook.xd.email). For mobile devices and anything relying on Exchange Web Services you can use owa.xd.email.
2a. Problems with Outlook. Please read https://www.exchangedefender.com/blog/2020/06/exchangedefender-exchange-setup/ almost all Outlook tickets are addressed with this. If you can login with OWA, if you have run autodiscoverregistryhacks.zip batch file as Admin, if you have Outlook 2010 with latest patches or newer - you should have 0 problems connecting to OWA.
3. Empty mailboxes, missing last week, etc. There is no reason to worry, we have mailboxes archived 3 different ways so if you can get into LiveArchive or had a domain org, we've got your email. We're replaying it but it is moving slooooooow. Essentially the process searches a temporary mailbox, locates messages sent to a specific primary email address, and then pushes those messages up. For blank mailboxes, described yesterday, they will be reseeded as well. Everything is moving in the right direction, we just need time. We're pushing the system to the limit in terms of traffic.
4. OWA "Lite" mode. Please do not use popup blockers on Outlook Web Access. If you do, it will block several critical components OWA has and it will launch in a light mode that looks like OWA from Exchange 2007. Just add it to the trusted sites or disable popup blocking on it. The theme can be managed through Outlook settings.
5. We have seen some NDRs that we are still investigating. So far we can explain away all of them (DKIM errors from LiveArchive, missing aliases, old organizations previously removed from Exchange org recreated because the migration has been staging since November!)
6. We have seen a few mobile device reports (calendar sync) that we are still investigating. We as of yet do not know if this is an issue, if the Outlook app is reprovisioned/reconnected properly, etc. In general, all mobile devices should use the owa.xd.email as the "server" and their UPN (login) and password.
06/08/2020 00:47 AM 15 days
9 PM Update EST:
At this point we have moved, created, troubleshooted, and sync'd every clean mailbox in our enterprise and all accounts are active and working.
Any mailbox that we could not successfully autoreconnect to the new organization is being created from 9PM to 11PM and mail will be replicated into it manually.
This move assures that access to email is restored for everyone on our platform, regardless of Outlook/Exchange instrumentation problems. It also puts every inbox into the service manager and gives our clients the ability to manage their mailbox immediately. If you're having issues, create a new profile, reconnect the mailbox and all your data will sync down either immediately for active accounts and shortly for accounts that have been reported as inaccessible via OWA. We are doing this so that everyone can use OWA and Outlook immediately.
If you choose to setup a new profile, you're set. If you do not create a new profile, your Outlook will start up and give you two options "Use Temporary Mailbox" or "Use Old Data" - please click on "Use Temporary Mailbox". Here is a pic of the screen for reference:
06/07/2020 21:27 PM 15 days
5:30 PM EST:
We are continuing to go through accounts of everyone that reported an issue. IF you reported an issue OR IF we are unable to login with any legacy/2016 credentials, we are continuing to work through those accounts and your mailboxes WILL be online tonight.
In terms of setup, the servers are owa.xd.email and outlook.xd.email, but neither is neccessary if your autodiscover is set. If you have/had an autodiscover, it does not need to be modified, all the autodiscover instances point to the new infrastructure. Make sure you've run autodiscoverregistryhacks.zip as the Administrator on the workstation, reboot and Outlook will restart. If Outlook was open the whole time during the move, you may get the prompt saying "The Microsoft Exchange administrator has made a change that requires you to quit and restart Outlook." but the result will be the same, Outlook will restart on the new infrastructure with your folders and new email in the Inbox.
06/07/2020 17:05 PM 16 days
Noon:
We are continuing to go through all the tickets and confirm / double check every account. We've been following up with clients that have contacted us via tickets, Facebook, SMS, email and providing passwords, reconciling the view in the Service Manager.
We are anticipating that this process of double-checking every single account will be completed by 3-5PM EST today at which point we would have confirmed everyone that has raised an issue is online (and many others that have not).
Mail flow to everyone is resumed as soon as their mailbox is online and redeliveries are happening so we're confident that as soon as we clear the list above we can say everyone is online and running without issues.
06/06/2020 14:34 PM 17 days
10AM EST
We are continuing to work on the tickets and reports of users that have not been able to login, many of these have been resolved already by our partners (by changing the password) but we will not leave a single ticket alone until we have been able to confirm everything is operating normally. This is an extremely important step in a migration because small issues in migration can cause larger issues down the road. (many of the accounts that did have problems had them because of a very custom / complicated configuration such as having multiple domains in the same organizations randomly used for authentication, clients opening 5 mailboxes in a same Outlook profile and typing in the wrong password, odd permissions, etc.) This is not to place blame on anyone that had such a configuration, we understand that every business has legitimate business process and operations needs, but when Microsoft & support tools we have at our disposal decide to stop supporting such configurations we have no easy means to recover them and it becomes a hours long ordeal or surgery.
We are still going through the tickets at this hour, we are waiting for the last few mailboxes to complete retry/reseed/retransfer/redo before we apply recipient policies so we can redeliver email that went into catchall mailboxes, intermedia failover authorized relay queues (so we don't bounce stuff that can be delivered), etc. None of these "missing" items are missing from LiveArchive, so if you're missing anything keep in mind you've had a LiveArchive mailbox since the day you signed up for ExchangeDefender for occasions exactly like this one. We have even deployed free LiveArchive for clients that purchased our barebones entry level Essentials products.
We are continuing to work on this and will provide updates as well as the timeline because the next steps are not reliant on using Microsoft tools (no PowerShell scripts with no progress or status indicators).
We have been heistant to introduce any other workarounds during this window as we were completely blindsided and needed to recover full access to as many people as possible. This will never happen again. Over the weekend we are working on some solutions that will greately expediate the self management of these mailboxes and authentication/ID processes.
06/06/2020 06:55 AM 17 days
Midnight
Most of us are still here going through tickets and double-checking every failed login, mail bounce, and recipient policy. This part is currently underway and we anticipate completing it by 8 AM EST when the next post will be published. This step is critical in applying all the missing distribution group, alias, security policies, public folder permissions, folder mapping, etc. At that point, all "missing" mail that was not delivered to those aliases/dgs will be replayed and delivered.
We are still monitoring a few mailboxes that failed import/connection to the appropriate Exchange organization. Exchange mailbox import can fail after a certain threshold of bad items in the mailbox (we started with 50 and are currently at 100). Because all of these mailboxes currently have LiveArchive and can work, we're resyncing some of them.
We continue to see tickets regarding Outlook connectivity. If it works in OWA, it will work in Outlook. If it doesn't connect in Outlook 1) Download autodiscoverregistryhacks.zip, run "cmd" as Administrator, reboot 2) Confirm the workstation can resolve autodiscover.YOURDOMAIN.COM 3) Check OWA at https://owa.xd.email and confirm that you have the right credentials 4) Open your Outlook (2010 with all service packs or newer) 5) Start Outlook. You will be prompted to accept new configuration, or "repair/rebuild mailbox", or "follow mailbox to the new server" and after accepting all of that... your Outlook will open up, sync up all your folders and you're back where we started just with the most up to date version of Exchange possible.
The next update will follow at 8 AM EST. We are continuing to work through the weekend and hope to be able to sleep soon. Thank you for your patience and kind words through this process, we realize this is a giant inconvenience and a business interruption.
06/05/2020 22:37 PM 17 days
Update 6:30 PM EST:
We have spent the entire day troubleshooting mailboxes across domains. The most common issue is the login mismatch, where users are using the wrong UPN or wrong username. We have been troubleshooting some tickets with missing aliases / distribution groups (those will be reapplied and mail redelivered), etc
We have been updating clients throughtout the day so if you opened a ticket this week you will get an update on your user/domain as soon as we confirm that they can access Outlook / OWA (this has been our protocol throughout the week).
Next update will be tonight at midnight, we are currently working on mail routing reports, troubleshooting reported failed OWA/Outlook logins, PF/DG/AL outstanding imports/issues/debugs.
Thank you for your patience. We are moving through this slow and tedious detailed work as fast as possible, every issue in this migration will be addressed. If anyone has ever unplugged a cable during a migration, PC update, or similar that's the disaster we had to clean up (but with certificates, authentication, routing, etc) that was crash dumped into our lap.
06/05/2020 17:07 PM 18 days
Update as of 1PM:
The only issues we are still seeing is related to authentication, password failures and resets. Team is moving through them quickly.
Several Outlook tickets came up, please follow directions in this post (https://www.exchangedefender.com/blog/2020/06/exchangedefender-exchange-setup/). If they do not have Outlook 2010 or newer, if they do not run the autodiscoverregistryhacks.zip file on their PC with administrative privileges, if they do not reboot, Outlook will not connect to Exchange.
06/05/2020 12:01 PM 18 days
7AM EST
As of 6:23am all mailboxes have been reconnected in the new environment. Everyone should be able to access their mail via Microsoft Outlook, Outlook Web Access, LiveArchive, etc. The instructions on how to handle misc issues is in this NOC post.
As of 5:30am all mail routing issues have been addressed and ExchangeDefender is delivering to all platforms as usual.
All access is fully restored to Microsoft Outlook, Outlook Web Access, and recovery systems.
We will be spending most of the day working wth clients and partners with login issues. Most people do not know their Outlook password, and misc issues surrounding Azure AD and AD congestion have slowed down credential resets earlier in the week. Today our final priority is helping the users with these authentication issues.
06/04/2020 22:28 PM 18 days
6PM Update
We are continuing to go through misc Exchange issues and mailbox reconnections. We believe we have at this point sorted out all but the following service items which we are working on at the moment. The biggest issue today was continued latency in Active Directory, something that we've addressed and solved as of 4:30 PM. Here is a summary of what we have left:
Mail routing and delivery
At 6PM we solved the issue of roundabout mail routing for mailboxes that have not been connected yet. Because the rug was pulled under us on Sunday we have been exceptionally aggressive towards archiving - so any mail that couldn't be delivered to the primary email address would be routed to LiveArchive, to catch-all domain mailbox, and a failover node.
Items in LiveArchive that are not in OWA/Outlook
This is related to the routing/delivery of the mail between various failover systems. Good news is because we have written LiveArchive for this very reason, we will be able to sync Sent Items right into their Exchange mailbox.
Mailbox moves and remounts
We are doing the final sweep of mailboxes that have failed to mount. We still have a few partners that are affected.
06/04/2020 13:55 PM 19 days
Important:
0. Download and run the registry files as the administrator, regardless of whether you already have autodiscover or not. The file is here: https://www.exchangedefender.com/media/autodiscoverregistryhacks.zip
1. If you already have an autodiscover record DO NOT CHANGE IT. We are
2. If you do not already have an autodiscover record, YOU DO NEED TO CREATE ONE. autodiscover cname autodiscover.xd.email.
The trailing dot is important, depending on your DNS software. You can tell if you've done it correcltly if your DNS lookup looks somewhat like this (from Windows 10 command prompt):
nslookup autodiscover.ownwebnow.com
Server: 65.99.255.161
Address: 65.99.255.161#53
autodiscover.ownwebnow.com canonical name = autodiscover.xd.email.
autodiscover.xd.email canonical name = autodiscover.dal.xdmail.online.
Name: autodiscover.dal.xdmail.online
Address: 72.249.54.208
If the autodiscover is missing, you will get an error instead:
nslookup autodiscover.xdref.com
Server: 8.8.8.8
Address: 8.8.8.8#53
** server can't find autodiscover.xdref.com: NXDOMAIN
----
To figure out if your workstation can detect the autodiscover record, Start > cmd > nslookup autodiscover.YOURDOMAIN.COM (substituting your domain name for it)
06/04/2020 13:30 PM 19 days
9AM Update:
We are moving through our tickets, resolving any outstanding issues, and keeping people in the loop here and support.ownwebnow.com
1. One of the things we are noticing more and more is that some people do not have autodiscover setup. If you can login to Outlook Web App (https://owa.xd.email/owa/) or NGE, then your credentials are good and your mailbox is online; so if Outlook continuously prompts for a password or takes forever to start up a session, confirm that you have an autodiscover record and that you have run the registry hacks. The process is described here: https://www.exchangedefender.com/media/ExchangeDefenderExchange.docx
2. Overnight we added some more horsepower to our LiveArchive NGE, it's actually moving faster than Exchange at this point so we hope the improvements make it easier to work.
3. We were able to identify and fix the internal routing issues, some clients reported that they saw some messages in LiveArchive that did not show up on the Exchange side. The same issue affected many login failures (from time to time, not completely), some mail delivery, (it's in the catchall), etc. We believe the changes that were made overnight will allow user logins to proceed without an issue.
4. If you have an Office365 version of Outlook, or if you setup your outlook 5-10 years ago with autodiscover but are now running on the latest one, you will still need to get and run as administrator (and reboot) in order to enable non-Microsoft Exchange servers. If you HAVE autodiscover and you are still getting repeated password problems, please follow the instructions in our guide on how to download and execute the patch, reboot, and after a minute or two it should be fine.
5. If you've never had Autodiscover, manual server configuration has been decomissioned by Microsoft in Exchange since 2013. We recommend setting up a new mail profile (Start > Control Panel > (Click View > Small Icons) > Mail (Outlook 20xx) > Show Profiles > Add) and you'll be able to setup a new autodiscover profile without destroying your existing one.
6. We are preparing to roll out swing mailboxes for the few mailboxes that we still have not been able to attach.
7. Staff will be spending most of the day following up. If you can, please keep all ticket updates on the same ticket, we are going through issues domain by domain.
8. Please use OWA if possible, please use NGE as possible.
Next update will follow later today but
06/04/2020 07:06 AM 19 days
3AM Update:
We are continuing to work with our partners and clients on getting users to the modern Exchange standards. Microsoft no longer supports "manual" server configurations as of Outlook/Exchange 2013 so if you do not have an autodiscover record you need to create one immediately (simply create an autodiscover CNAME record in your domain with the value "autodiscover.xd.email"). We know that many of our partners and clients aren't highly skilled in obscure Microsoft Exchange settings and configurations so we've written up a quick guide that just about anyone with Admin access to their PC or mobile device can follow:
https://www.exchangedefender.com/media/ExchangeDefenderExchange.docx
Please feel free to distribute the document or customize/brand it to your liking. The process is very simple, as long as you can login to Outlook Web App (https://owa.xd.email/owa/) those same credentials will get you into the new version of Exchange.
If you have autodiscover configured already (you should, without it even 2013 and earlier barely worked consistently) your Outlook will prompt you for your password. You may get an error or warning and within a few minutes a screen prompting you to accept new settings from "outlook.xd.email" will show up. Click on accept, Outlook will open your mailbox and everything is done. If you experience a problem in this stage, start Outlook in debug mode (outlook /rpcdiag) and observe the servers it connects to - if it's Office365 you will need to follow the same steps in the guide for running Outlook Registry Tools.
In terms of backend work, we are still helping partners mainly with authentication and mail flow problems. We still have a few users that are failing auth because of all we've discussed before, we're confident these last few changes will make things move smoother.
The most difficult issue for us remains communication and ability to update so many clients and partners, and troubleshoot smaller issues with individual mailboxes and organizations. We remain confident that even though we've been dealt this setback, we will have everyone on the new platform and it is well worth it. Next update will be provided at 9am.
06/03/2020 20:02 PM 19 days
4PM Update
We are continuing to see the NGE environment normalize and people return to work. There are still some issues that we're trying to get to the bottom of (already covered in previous NOC posts, Outlook/autodiscover/password resets just not being as consistent; we have been troubleshooting these on the backend). For the most part, everything is working - and we have a number of users that are still not online that we're going above and beyond to restore the service where Microsoft tech is simply incapable of doing so (see below under IMPORTANT - PLEASE READ if you're still down)
The biggest issue at the moment is on the staffing and technology side. None of us have left since Sunday and our original migration and transition plan had to be compressed down and executed quickly. Our support is simply not capable of handling tens of thousands of tickets so we have been consolidating them per MSP and per domain and trying to get as many up and running as fast possible (see TECH DETAILS section) but some clients are understandably frustrated with the outage and creating dozens of tickets which is only slowing us down. Requests for a callback, to recite what we have in these NOC updates, is also slowing us down. We are on your team, we have your best interest in heart and it does not help us at all if your clients leave you. We take our responsiblity to our clients seriously and are doing everything we can to get everyone up and running - but we're overwhelmed and exausted and beaten and I'm sure everyone in IT can relate to that. We're working on it. Below is a brief technical summary for the outstanding clients that are down, an explanation, and a workaround.
TECHNICAL DETAILS - IF YOU ARE STILL NOT ABLE TO CONNECT
The remaining mailboxes that are still not online fall into two technical categories.
1) They have moved/moving and the O365 side has failed to reconnect the mailbox to the domain or we are attempting to move a mailbox and it errors out and fails after it reaches a failed item treshhold. The reconnection process and seeding process fails and we go through a manual attempt through PowerShell to map the mailbox to it's proper location so Outlook/OWA/EWS(mobile) can connect to it. There are tons of different technical issues here (from not meeting basic password complexity, one user had P@ssw0rd as a password - to bad X400 address / primary address mismatch / etc). Rinse, then repeat, over 700 times since Sunday. We're down to only a couple that are in this stage.
2) They are still in process of moving - These are mailboxes that were never flagged for move because they were renamed, had weird / circular permissions or other misconfiguration, OR, they got disconnected from the move when the source was disconnected. For these, we are moving them to production but some users have 30-40GB mailboxes and the process of migrating is slow. Once they are moved, we go back to step #1 and confirm that they can login. Then someone in support has to dig up the correct ticket and update it.
We are currently working with partners over the phone, over our NOC, over Facebook video/chat, over txt, and we're doing everything in our power to connect the remaining accounts. This is brutal and difficult and we understand how bad it is - and we are here working for you and trying everything we can to get everyone online as fast as possible. This whole episode was not our plan but Microsoft pulled the rug from under us and we're doing insane stuff just to get everyone working. See below:
IMPORTANT - PLEASE READ - IF YOU'RE STILL DOWN AND WANT AN IMMEDIATE WORKAROUND
If you do not want to rely on LiveArchive or NGE, or wait for the mailbox to be repaired/restored/reconnected/etc we can bring you to operations quickly - but fair disclosure, this is ugly yet functional. The following process can be executed by our NOC to create a temporary mailbox that we can then merge together when the original mailbox is ready.
Create a new mailbox with a unique email address swing.USERNAME@domain.com. On the edge transport servers we will create a rewrite rule which says mail from the swing address gets rewrote to the real address and mail to the real address is rewrote to the swing address.
The user will have the same display name with an extra space so Vlad Mazek => Vlad Mazek
We create a transport rule for intra company mail to redirect to the swing user.
At this point, all their mail flow is working fine and they can work out of OWA.
After completion
Once the migration is completed, they’ll be closed out of their swing mailbox (or we can give it full access permission to the real mailbox so it automagically shows up in owa/outlook). The real account is then active for login and we disable the rewrite rules and import the data from the swing mailbox to the real mailbox.
06/03/2020 14:31 PM 20 days
With almost all mailboxes reconnected, we are now addressing mailboxes that are in a failed/disabled state. These mailboxes are disabled for a variety of reasons (account or domain mismatch, account deleted, not in the right security group, etc) and we're enabling them, clearing any errors, reconnecting.
We already know which mailboxes are in this state and we're working through the list, in the meantime please stay in LiveArchive if your mailbox is affected by this and we will update the existing tickets as we go along.
I know many of our partners are asking for an update and specifics to pass to their clients and we'll offer a detailed writeup by noon on www.exchangedefender.com/blog
06/03/2020 08:33 AM 20 days
4:30 AM EST - The mailbox process is nearly complete, we have resolved a number of reported issues overnight as well. Our next step is to deliver PF and catchall mailbox access.
06/02/2020 21:38 PM 20 days
We are at the tail end of getting everyone off the legacy platform, and we have restored access and mail flow to just about everyone. The last few mailboxes are exceptionally difficult and we are doing everything in our power to get them completed before midnight, but a few may slip. Here is a summary of work and issues we've resolved throughout the day in case you expereinced any of these problems we hope you can check again:
1. LiveArchive NGE DKIM signature - our infrastructure was not signing DKIM messages, in interest of expediency we've routed outbound mail via ExchangeDefender instead of implementing DKIM on the platform for all of our client domains.
2. Occasional 504 gateway timeouts - these typically happen when our backend docker services do not respond in time to the frontend proxy. We've bumped the resources and timeout settings there throughout the day and it's performing well considering exceptionally high usage.
3. "Report Issues" button in Service Manager - several of you have found it, it's something we've been trying to sort out throught the day so we can avoid doing individual service requests through support tickets. We can automate a lot of the discovery and analysis through this and get users problems autofixed going forward. Please note that this is not going to help mailboxes that aren't already mounted, this is more for the ongoing support.
4. Active Directory resiliance - we are adding more domain controllers to the mix. These will not go online till midnight for our clusters located in USA, and until tomorrow for EMEA/AUS.
5. We are sorry about this, we understand the frustration and we're doing all we can as fast as we can to get everyone rolling in the right direction. The rug was simply pulled out from underneath us with no warning and our actual migration checkup plan that was supposed to last 2 weeks on 6/15 had to be executed in 1 day.
Next update will follow at 9:30 PM EST.
06/02/2020 16:37 PM 21 days
Noon update: We are in the final stages of reconnecting and disconnecting all the affected mailboxes (some larger mailboxes are requiring a reseed so if you haven't gotten your users and mail enabled public folders onto LiveArchive, this update is specifically for you).
https://www.exchangedefender.com/blog/2020/06/update-exchange-migration/
We have also addressed an issue where catchall mailboxes (catching/caching mail for inbound) are accepting messages but still issuing an NDR. Followup post will explain how to access that mail shortly.
We are optimistic about the current progress and believe we've addressed all the unexpected issues that have come up since Sunday. We will keep you up to date on our progress on the NOC site at www.anythingdown.com.
06/02/2020 13:04 PM 21 days
9AM
We have largely restored access to practically every mailbox that had a simple fix and are now making additional passes over mailboxes and organizations that had custom configurations or other errors preventing them from reconnecting manually. The process of updating all tickets, clients, and mailbox configs is manual and time consuming so we've been working on a few things that will be announced ~10AM EST today.
1. We are prioritizing getting LiveArchive NGE (launched last month) access for users that are still affected. We will have a quick walkthrough on how to create accounts for public folders/etc so at least people that are still affected can get email.
2. The manual reconcile process is moving forward.
3. No additional issues have been reported, which is the only good news to report since Sunday, and our goal is to make sure EVERYONE can quickly recover
4. All tickets are being consolidated per company so we can keep you up to date better and we're discussing our update policy. We're all in the same boat here, while we are working as fast as possible and realize that everyone has a critical issue, everyone is upset or livid (as are we) --but we can either work on getting you online or we can deal with "ETA", "What do I tell my client", "This is still not working" ticket updates that are just putting all of us at a disadvantage. Priority is getting people email, there will be plenty of time to make everything right and reconcile things.
5. New UI and LiveArchive tweaks are being put in to allow people to manually address LiveArchive login/etc separate from Microsoft Exchange, so that mailboxes that are still affected and so that users that live in Public Folders or have mail flow interrupted for whatever reason, can continue to work.
We thank you for your patience and are working as hard and as fast as possible.
06/02/2020 04:11 AM 21 days
Midnight update:
We are still going through cases and repairing/activating in the debug queue. More accounts are reconnected and verified, we are working through the queue. If you've reported the issue, or if we identified an issue with an account, we are working on it (and tickets will not be updated until either there is a new NOC update with our progress or we have verified we can login and manage all accounts in the domain).
We hope to have all issues (except Public Folders) addressed shortly, we will have a new process for reporting outstanding issues in the AM for users that are still reporting problems.
06/02/2020 00:10 AM 21 days
Update 8PM EST:
We are currently working through a project queue that our partners and support team setup throughout the day to address any outstanding accounts that are having login issues. We are prioritizing authentication requests at this time and will be working through the night as long as it takes to get everyone into their Inbox. At the moment, the second biggest issue we are working on is related to reattaching Public Folder infrastructure to some organizations. We will be updating support requests as we reconnect entire organizations, and will kickstart PF reconnection afterwards.
More details: Remaining mailboxes that are currently inaccessible and password reset does not resolve the issue did not successfully move to the new organization and disconnect from the source (problem causes involve Active Directory errors, Exchange errors, password complexity) and the recovery process is to simply check the error, make required adjustments, and attempt to reconnect the mailbox. Because each issue is separate and caused by different factors, this is a slow manual process. We are working on it and anticipate everyone will be reconnected/restored tonight. There are several mailboxes in the move that were never picked up by the Migration Engine and we're manually moving those accounts too but some of the larger mailboxes are taking time, thankfully there are rather few of them and we have tons of resouces.
We will keep you up to date throughout the night and we are very sorry about the inconvenience this has caused our users. We're doing our best to get everyone up to speed and we realize that everyone has an urgent need to get back to their Outlook, we are here for you. In the meantime, we hope you can continue to work out of LiveArchive at https://nge.exchangedefender.com as we get this up and running smoothly, the level of complexity and issues with the legacy Exchange platforms has been significant and we have planned this process for months and executed countless test runs with very few issues. We realize that it doesn't matter how thought through and designed the process is if you can't login to your mailbox right now and we're continuing to work on this.
06/01/2020 19:43 PM 21 days
Update as of 3:30 PM EST:
All but ~200 mailboxes have been restored, mail flow has been showing as nominal since it was activated this morning. The mailboxes still in manual debug are on organizations that have changed UPN or had some more complex settings that we are reconciling and activating manually.
1. The biggest update since the last NOC is that all organizations have been moved to our next gen Service Manager. If you see your organization in there you should be all set and all functionality (password changes, etc) is functional. ***IF*** you changed a password during any time and were not able to login to our new https://owa.xd.email/owa/ site, the password you set is likely in queue waiting to be applied to the mailbox. Once you can confirm you're good with OWA, Outlook should automatically offer to repair a profile and restart in the new one (no mail download, everything just starts working)
2. We are still working on reconnecting some PF for several organizations, this is done automatically on the backend.
3. If you experience this issue with Outlook 2010:
Microsoft Outlook: There is a problem with the proxy server's security certificate.
Outlook is unable to connect to the proxy server cas.darkwing.exchangedefender.com. (Error Code 8000000)
Start > Control Panel > Mail > Show Profiles > Properties > Click on Repair
That will force Outlook to go out, check with Autodiscover, download the certificate, and apply it correctly.
This only works on Outlook 2010. After that, the profiles automatically repair/redownload.
06/01/2020 16:41 PM 22 days
06/01/2020 15:07 PM 22 days
Mail flow to all our Exchange clients has been restored, along with distribution groups, shared mailboxes, etc. We have a few more tasks but all our Exchange clients should be in production.
We have received reports from some users that their passwords aren't working in Outlook. If you are experiencing this problem, please update the ticket with the list of email accounts (UPN) that are having an issue and we will start troubleshooting them. For the time being, if you are experiencing login issues please keep users in LiveArchive at https://nge.exchangedefender.com and OWA at https://owa.xd.email/owa/ (the trailing slash at the end is required, just typing in owa.xd.email will not work for now)
P.S. NO configuration (DNS/etc) change is required, this process is largely transparent. At most, you will have to click on OK/Rebuild/Restart when Outlook attempts to open the mailbox on the new infrastructure.
06/01/2020 13:22 PM 22 days
We are in the final stage of the checkdown, reviewing the Public Folder and Distribution group transition. We're working as quickly as possible and look forward to restoring Outlook service momentarily, please keep your users in LiveArchive for the time being (it works on mobile phones too)
06/01/2020 11:14 AM 22 days
As of 7AM the migration has been completed and we are nearing the end of all the error checks with the hope of restoring mail flow and Outlook connectivity shortly. We are still working on a few items (public folders, changed UPN accounts).
05/31/2020 23:12 PM 22 days
We are currently in the final stage of finalizing moves from our Exchange legacy platforms/clusters to the new 365/2016/2019 SKU. The work is expected to be completed before midnight, May 31st, 2020. While we do not anticipate any issues and have tested everything thorouhgly, things in IT (and legacy apps) can cause problems and we've stepped up our staffing to help our partners and clients work through them all.
In the meantime, if your mail flow or access to Outlook gets interrupted, you are not down. There are two failover systems at ExchangeDefender you can rely on to continue working:
ExchangeDefender LiveArchive: https://nge.exchangedefender.com
Outlook Web App: https://owa.xd.email/owa
We will keep you updated on our progress here at www.AnythingDown.com and at https://support.ownwebnow.com
At approximately 11:45 AM EST we were forced to restart our primary database clusters for an urgent performance issue that could not wait until after hours.
If you received "504 Gatweay Timeout" error from one of our web services it had to do with the service restart. As of 11:52 AM everything is back to normal.
We have been working with Microsoft today to address an apparent outage. The firewall and access rules have been reconfigured and our tests at this moment suggest that the issue has been resolved and mail is no longer being rejected as of 5:30 PM.
Our systems were processing the messages on behalf of our clients correctly and delivering them to the correct Microsoft endpoint, where connection was authenticated and recipient/detail exchanged. At that point Microsoft issued a 4.x.x temporary failure error ("Server busy. Try again later..") and ExchangeDefender continued making delivery attempts with some Microsoft servers issuing a 4.x.x error, some rejecting it with a 5.x.x, and some processing messages correctly. We have been in touch with Microsoft throughout the day and were able to have it addressed. As of 5:30 PM there doesn't appear to be an issue.
The certificate has been renewed and applied to the load balancer.
05/18/2020 12:17 PM 5 days
r.xdref.com is showing an Expired Certificate.
We are in the process of correcting this.
We are sorry for the inconvenience.
Access to all services is working according to our testing. We have a few things to wrap up but the fixed upgrade from the vendor appears to be working as intended
05/16/2020 03:20 AM 7 days
The swap has completed but some services are still inaccessible. We're working on diagnosing the issue.
05/16/2020 01:44 AM 7 days
We will be setting our primary firewall back into active service which is to reverse the activation of the backup firewall
From 11:00 PM - 11:10 PM Eastern service access will be intermittent while the connections stabilize
This has been resolved, and reportedly affected mailboxes are successfully logged in at this time.
05/15/2020 17:38 PM 8 days
We are currently investigating an error some mailboxes are giving at login:
Your mailbox appears to be unavailable. Try to access it again in 10 seconds. If you see this error again, contact your helpdesk.
Users can be directed to use LiveArchive as a workaround in the meantime, by signing into their account here: https://admin.exchangedefender.com/livearchive.php
Thank you for your patience and understanding during this process.
The update was successful, but appears to not resolve the issue with a previous update. We will be activating our backup firewall to allow our vendor to further diagnose the issue
05/06/2020 16:57 PM 17 days
We've received an emergency hotfix from our firewall vendors to apply to all edge controllers. We will be applying the hotfix tonight at 11PM Eastern and rebooting the ingress routers. During the install all inbound services will be interrupted until the reboot completes. We anticipate the update taking up to 10 minutes to apply.
certificate updated at 4:23PM Eastern
04/23/2020 20:19 PM 30 days
The SSL for rockerduck has expired and was not swapped out. The certificate has already been renewed and is being distributed to the front end nodes
During a schema upgrade dry run, a failure was detected which caused our monitoring software to rollback the latest backup on disk. This has unfortunately reverted changed from the past 48 hours meaning additions and changes to exchangedefender domains, users etc have rolled back. We are pulling the offsite copy from this morning and are working to restore the correct data structure.
As of 10:07 EST everything is operating normally and there have not been any new reports of an issue.
04/13/2020 12:33 PM 10 days
Mobile email connectivity is reported to be impacted for users on Louie. We are actively investigating the issue.
Service was restored around 2:13 PM Eastern
At 1:51 the OS on the primary mailbox server forced a restart. At the time of the reboot, the replicas were 8 minutes behind and could not automatically fail over without force. Upon checking the crashed server, it was already in the process of loading into windows. We elected not to force a fail over as we did not want to lose the pending 8 minutes of data. Prior to the reboot, we had reports from various partners regarding IOS connectivity and OWA connectivity. We're still monitoring the situation, but at the moment all services are reporting operational.
04/06/2020 17:56 PM 17 days
Our monitoring has notified us about access issues to GLADSTONE starting at 1:53 PM Eastern. We are actively investigating the issue.
Mobile email connectivity was impacted for users on Gladstone and our backend team has made an adjustment on the server and expect mailflow to return to normal on mobile devices for these users.
If you have users reporting issues from earlier today and have not yet opened a ticket we request that you please have your users try again as this is reported as corrected and first users are reporting fully restored functionality.
Thank you for your patience and understanding at this time.
Network access and latency issues were resolved within minutes of this NOC alert being opened. We have resolved the issue temporarily and will put in a more permanent fix in the off peak hours during maintenance cycle.
03/31/2020 15:52 PM 23 days
We are noticing increases in request latency for bot web UI portals and mail flow. We're currently investigating the cause.
At 11PM Eastern we will be performing an emergency firmware upgrade to our core ingress firewall. During the upgrade, all services will be temporarily interrupted for five minutes. If we run into any issues after the upgrade, we will activate our backup ingress firewall which is running the current configuration and firmware.
We are working on several network services today as we anticipate the growth in usage across all our services. We are currently experiencing degraded performance on our database servers which is slowing down and timing out some services. More capacity is being onboarded, we appreciate your patience with us while everything syncs up.
Service was fully restored around 11AM Eastern with no further issues reported by our partners
03/19/2020 14:15 PM 4 days
We are actively working to resolve intermittent access issues to 2016 mailboxes. Mobile phones seem to be the least impacted, followed by Outlook and then OWA. We anticipate all connections stabilizing by 11AM Eastern but customers should see performance increases as we update throttling policies.
We've implemented our work around solution and we're seeing dramatic improvements in response time. We will continue to monitor the performance and work on fixing the underlaying issue with mail routing through LAX. At the moment, there are no observed delays
03/11/2020 13:46 PM 12 days
We've reconfigured our LAX data center to proxy as much mail traffic through Dallas to alleviate any mail delays that were observed yesterday as we continue to repair an issue in LAX. Unfortunately the increased load in Dallas is causing occasional timeouts on sites like support.ownwebnow.com, admin.exchangedefender.com, etc. We are close to implementing another workaround solution which should resolve the mail delays from yesterday without impacting the performance in Dallas
We've implemented our work around solution and we're seeing dramatic improvements in response time. We will continue to monitor the performance and work on fixing the underlaying issue with mail routing through LAX. At the moment, there are no observed delays
03/10/2020 14:35 PM 13 days
We've re-enabled our LAX datacenter and we are processing mail in both locations. We will monitor the load distribution over the next 15 minutes and update this NOC when service is fully operational
03/10/2020 14:18 PM 13 days
We're working on an issue with our secondary datacenter. For the time being, we've disabled mail from being accepted by our LAX and routing everything through our primary data center. We haven't seen any spikes in delays, but there is potential for 5-10 minute delays. We will update this post when all data centers are back to full operational status.
Our LAX cluster suffered a failure when logging SMTP transaction logs for search in the web UI for messages that arrived in the past 24 hours. Users will still be able to search and view the meta data of a message (from, to , subject, timestamp) but will not see the actual delivery logs if the message was processed by our LAX data center.
If you require the logs for a specific message, please open a support request with the meta information of the message and our staff will pull the logs from the backend.
As of 3:51 all users are confirmed as failed over and operations are back to normal. We will continue to work with Microsoft to ensure this bug / issue is properly diagnosed and leads to a more permanent solution.
02/25/2020 20:38 PM 28 days
Service restart has forced the mailbox instances to start failing over. We should have services fully recovered for all users shortly.
02/25/2020 20:24 PM 28 days
We are experiencing a minor outage affecting 84 mailboxes on our Exchange 2016 platform. Our teams are trying to determine why the failover did not occur correctly, and out of abundance of caution, we aren't terminating the system call.
In the meantime, all 84 users affected by this Exchange database outage can still send and receive email at https://livearchive.exchangedefender.com while the maintenance is underway.
All work was completed successfully and things have been moving smoothly since Saturday morning. The new configuration was tested and failover is now behaving as intended.
02/21/2020 06:50 AM 2 days
We successfully replaced the core router with a spare that we had on hand. We will still replace the unit with the shipped replacement from Cisco Friday or Saturday evening. This NOC will be updated once the swap out is completed.
02/21/2020 05:49 AM 2 days
We will be performing the hardware swap out in 10 minutes. Service is expected to be back online by 1:15AM Eastern
02/21/2020 05:11 AM 2 days
We're in the process of reprogramming one of our spare Cisco routers in order to temporarily replace the current master. We've elected to go this route to allow us to flip back to the original master without a conflict of configurations and addresses.
We will attempt to activate the spare router in one hour at 1AM Eastern. During the swap, users will not be able to access their mailbox. We've allocated a 45 minute window to perform the swap. If we are unable to complete the swap in the time frame we will revert the changes and continue to work on a temporary solution.
02/20/2020 23:03 PM 2 days
Our team has been working on this issue all day and after consulting with Cisco we are going to attempt a temporary solution that will hopefully minimize the impact to the 2016 infrastructure until the routers can be managed on Saturday, during our weekly maintenance interval where we can minimize impact and continue to serve our clients with minimal interruptions.
We understand this is a serious issue as any impact to performance is an impact to the productivity of the people we serve. We have been fortunate that Outlook is fairly resiliant and have only had a few complaints. Mail isn't bouncing, and disconnections only last from a few moments to a few minutes and happen every few hours. We will attempt a workaround at 2AM EST and hope to be able to restore performance to normal at least until Saturday when full maintenance cycle can be performed. In plain English: we're trying to patch it along so it can make it to the weekend where we can sustain a potential outage of 30 minutes.
02/20/2020 15:33 PM 3 days
We've identified an issue with a core ingress router to our Exchange 2016 network. We will replace the router during our core maintenance cycle this weekend. During the router replacement, we will actively keep connections from opening while we validate the performance and stability of the replacement router. We'll update this posting during the upgrade.
At 8:12AM our Dallas DC firewall infrastructure suffered a catastrophic failure and failover wasn't instant across all services. Failure in one of the firewalls disconnected several private VPN connections that isolate/separate and protect the ExchangeDefender's internal services. We were forced to restart firewalls, which had to reestablish VPN connections, which required all the services to reload configurations simultaneously as routing work was started to move traffic around and away from Dallas. At about 8:24AM all services have been confirmed as green and back in services.
We have double checked every system and everything is back to normal.
Outage lasted approximately 10 minutes.
02/13/2020 13:39 PM 10 days
Private VPN tunnels are back up and all the log, maillog, ips, services are verified to be back in sync.
02/13/2020 13:30 PM 10 days
As of 8:21 the routing and almost all the applications have been restored. We are still working on what caused the problem and how to mitigate it automatically.
02/13/2020 13:20 PM 10 days
We are working on a massive outage in Dallas. Service outages have been reported, we are working on it and will provide updates every 15 minutes as they become available.
As of 11AM, the messages that were delayed in our Dallas DC have been processed and delivered. All other data centers processed mail without an issue.
02/07/2020 15:51 PM 16 days
As of a few minutes ago all the new mail is going through the load balancers without delay, the mail that was delivered to nodes that were experiencing DNS/latency issues in Dallas is being processed at the moment and will be delivered in a few minutes.
We will be upgrading to a new database cluster at 4 PM EST on 2/6/20
During the upgrade all web UI services will be taken offline for 5 minutes. The services affected will be
Mail flow will not be interrupted at all during the upgrade
The issue with the clock drift has been addressed and time is displaying correctly on new messages. No mail was lost or delayed during this issue but some messages got a timestamp of up to 5 minutes in the future.
01/29/2020 16:45 PM 25 days
We've been addressing an issue with clock drift on one of our Exchange 2016 nodes. The drift is less than 5 minutes and should be resolved momentarily.
We are currently tracking large amounts of messages from recently registered .site domains that are forging their messages to appear as Invoicely. You may see subjects like the ones below, if some are released to your Inbox please delete them:
Past-due payment notification from Invoicely
Past due invoice notification from Invoicely
Overdue invoice notification from Invoicely
BT Internet DNS issue seems to have been addressed. We have no visibility into their network, however, one company has let us know that several items sent to BT did not make it to recipients mailboxes even though the delivery has been confirmed. Unfortunately, free email accounts and ISP email accounts tend to do this from time to time, the only option is to resend.
01/24/2020 17:41 PM 29 days
We are currently working with British Telecom to address an issue on their servers related to their implementation of synchronoss.net software. What our customers are experiencing, intermittently, are delivery delays while sending messages to btinternet and associated properties. The issue was first reported to us around 9AM EST and was quickly addressed to bypass/mask the ExchangeDefender network and route around the problem until BT has a chance to figure out why their DNS and outsourced mail service are having issues with DNS resolution.
Current error produced on their side is:
421 re-prd-rgin-021.btmx-prd.synchronoss.net Service not available - no PTR record for x.x.x.x
As of 10:15 AM this morning this issue has been addressed for our customers so they can send mail to BT, however, this is an issue outside of ExchangeDefender's control and free/ISP mail staff tend not to be very concerned about email delivery issues in general so we do not expect a quick resolution nor can we estimate an ETA.
The issue that caused performance impact and timeouts has been addressed overnight on the backend. We have improved the failover and load balancing of our container infrastructure that handles services that were impacted in our phishing.
01/23/2020 18:05 PM 30 days
ExchangeDefender SQL driven properties (admin, r.xdref.com, etc) are moving slower than usual today, we are allocating additional resources to the instances serving these services and expect the performance to return to nominal by 1:20 PM EST. The issue is within the ExchangeDefender cloud and is being addressed by our team right now.
We are presently experiencing a massive phishing attack originating in Russia targeting enterprise users from Office365 and beyond. All messages suggest that the invoice/order/bill/payment/transaction has been completed and encourages clients to click on a link that either has a dangerous malware payload or identity theft attempt. This is similar to the Azure and Amazon Web Services (aws) outbreak that has been gaining momentum for the past week.
If you have ExchangeDefender, you don't have anything to worry about - we're blocking their access to our clients and anything that does slip will be picked up by the ExchangeDefender Phishing Firewall which will block traffic to those dangerous sites.
If your ExchangeDefender service is managed by a third party (MSP) please check with them directly to see if they have blocked ExchangeDefender Phishing Firewall because that action would put you at risk.
Public folders are now online in the ROCKERDUCK cluster
01/09/2020 13:54 PM 14 days
We are working to restore access to the primary public folder database in the ROCKERDUCK cluster. Currently, users are unable to access public folders through all mediums. We anticipate restoring service within 20 minutes.
We received an alert about a single dismounted database. The original hosting server is indicating performance issues which has prompted us to activate a switchover for the database. We are working to restore service to the users on the affected database.
We have resolved issues with the proxy/redirection/caching that affected some LiveArchive logins. The LiveArchive login now inherits the functionality/style of all the other ExchangeDefender/Wrkoo products.
12/31/2019 20:26 PM 22 days
Some users are having issues accessing their Live Archive accounts, we are working on a solution. We are sorry for the inconvenience this may have caused.
We are currently investigating an issue with a certificate chain on one of the Exchange CAS nodes in the Scrooge infrastructure. If you've been disconnected your Outlook will attempt to reconnect automatically after a few minutes.
We are seeing failed requests for 13% of connections to LOUIE. We're currently investigating the issue
The issue should be fixed.
Please verify. Thank you.
12/04/2019 14:27 PM 19 days
Microsoft is currently making changes to their new servers. It appears the 365 team is using *.prod.outlook.com for newer servers vs the previous rDNS name of *.outbound.protection.outlook.com . We have added the new host name to the allowed list which should fix it.
We will monitor the situation. Thank you!
Malwarebytes have confirmed that the issue has been fixed and the site is whitelisted again.
Thank you for your patience.
12/04/2019 14:24 PM 19 days
We are currently receiving notifications of a false positives for our support site.
Please ignore this as it is a false positive. We are working on getting this removed. Thank you.
We've opened this issue again as there are still issues accessing services. We've temporarily disabled POP and IMAP connections to provide at least a reduced consistent connection
11/22/2019 15:38 PM 1 days
Service has been restored and mail is flowing. The original and replacement motherboard were both defective but remedied by a replacement motherboard that was overnighted to our datacenter.
11/21/2019 16:49 PM 2 days
We received alerts about the mail service included with webhosting being offline. We are beginning our investigation and will add additional notes to this NOC as progress is made.
On Tuesday, November 19th, 2019 we addressed a bug in the ExchangeDefender Phishing Firewall URL rewriting software that was improperly truncating URLs. Our partners at ReadyCrest Ltd identified the bug by comparing the length of the compressed, rewritten and raw URL and seeing that we truncate link after the first #.Usage of # tends to be fairly explicit in HTML emails and almost exclusively used for anchor links. These links don't actually connect to another site/document, they are meant to scroll the browser to a specific part in the web page. Typically they are used in a table of contents for longer pages, contracts, etc to move the browser to where the actual content is. The syntax is # followed by the name of the section to scroll to - so there is NO functional reason in HTML to ever have more than one # in the URL. That was key in our design and decision to drop anything past the second # - but we've now discovered that some sites may, in fact, put extra (typically reserved) special characters like # in the URL which breaks ExchangeDefender Phishing Firewall rewrites because it removes portions of the link.To our knowledge, this is the first reported link with multiple # in the URL, and going forward multiple # will be allowed in the URL without truncation.This issue has been addressed.
Access has been restored to users on the dismounted database. We are now investigating why the automatic failover didn't occur for the dismounted database.
11/13/2019 01:12 AM 10 days
A mailbox node in the LOUIE cluster lost one of its uplinks and has caused one database to become dismounted. Prior to losing the uplink, the node held 6 mailbox databases and five successfully failed over to another node. It is currently unclear why the single database did not fail over to a replicated node, but we will investigate it further after we've restored service. We're in the process of replacing the uplink and service should be restored shortly.
We are currently investigating the Encryption Portal and some users reporting issues with opening emails and seeing the subject from the Encryption Portal.
Please standby as we take a deeper look into this. Thank you!
This issue has been resolved. Thank you!
10/31/2019 22:18 PM 22 days
The invoices sent to our clients for November came with the subject "Monthly Services (December, 2019)" instead of November, 2019. We've made appropriate adjustments on the backend and everything is labeled correctly as of 6PM EST, October 31, 2019.
This issue has been resolved. Thank you!
10/29/2019 15:37 PM 25 days
We are currently investigating issues with portals in regards to our services.
Please stand by. Thank you.
The issue has been fixed.
All new email will reflect properly in the logs.
Thank you for your patience.
10/28/2019 17:23 PM 26 days
We are currently expecting some issues for SMTP logs for some domains. Logs are showing blank for a few domains.
Please standby as we fix this. Thank you!
This issue has been resolved. All operations are back to normal.
Thank you.
10/24/2019 14:05 PM 30 days
We are experiencing further issues on this specific server with SharePoint.
We will update once we have a resolution. Please stand by!
Thank you.
The issues were identified fixed with the servers.
Thank you for your patience in this matter!
10/22/2019 15:12 PM 1 days
We are investigating an issue with our message preview infrastructure, possibly affecting a few users on Encryption, Compliance Archiving, and SPAM Quarantines. The issue should be resolved momentarily if you have an issue with a preview loading just hit refresh.
Thank you!
The issues were identified fixed with the servers.
Thank you for your patience in this matter!
10/22/2019 12:26 PM 1 days
We are getting reports of certain domains not being able to log into their SharePoint sites.
We are investigating the issue and will keep you updated.
Thank you for your patience.
We've completed an upgrade to our load balancing infrastructure. These servers and switches take on the traffic from the Internet and pass it on to appropriate inbound nodes in the ExchangeDefender cloud for processing. While we have been hoping to roll out the upgrade to the load balancing infrastructure later in November during the long Thanksgiving holiday, we simply needed next-gen stuff immediately. The event that occurred on Wednesday, October 16th, 2019, would have been fully and immediately mitigated by the new load balancers so we are hoping that this upgrade starts performing well for our users immediately. We activated the new load balancer in our primary location (Dallas) at midnight on October 17th and immediately saw a performance gain on the processing speed for inbound messages.
The issue at hand has been fixed.
Please verify that the page is working properly.
Thank you for your patience.
10/04/2019 13:56 PM 19 days
It has been brought to our attention that there is some user currently being affected by performance issues on https://admin.exchangedefender.com/
We are currently investigating the issue.
Thank you for your patience. Please standby.
The certs have been refreshed
09/17/2019 14:06 PM 6 days
Tonight at 11PM Eastern we will be restarting the load balancer service for 2016 to use the renewed SSL for the root domains. Access should only be interrupted from 11:00 PM - 11:05 PM Eastern.
Thank you for your patience.
The Engineering team has adviced that the issue has been fixed.
Please have all users affected by this and verify. If you are still facing issues please open up a ticket on Support Portal, please.
Thank you.
08/29/2019 11:18 AM 25 days
We are currently experiencing some SSL Certificate issues with xdref.com. We have identified the issue and are currently working to resolve it.
In the meantime have users Click on Advance and select Proceed to r.xdref.com
This is so they can still keep going to their links.
We appreciate your patience.
Thank you for your patience.
The developers have advised that this issue has been fixed. It was due to a small bug that was easily and quickly repaired.
Please have any users previously affected by this issue try again with reading any messages.
Thank you.
08/27/2019 19:29 PM 26 days
Some users are experiencing issues with the Encryption portal (Error 1).
We are currently investigating.
Please standby.
Access has been restored to public folders.
08/22/2019 16:03 PM 1 days
Customers with public folders are unable to access public folder data. We're working on restoring access as quickly as possible
Thank you for your patience in this matter.
The issue at hand has been fixed. If you are still experiencing issues please open up a ticket on here.
Thank you.
08/16/2019 16:45 PM 7 days
We are currently facing some issues with the Della Server.
Please have users use LiveArchive while we pinpoint this issue.
Thank you for your patience.
Thank you for your patience in this matter.
The issue at hand has been fixed. If you are still experiencing issues please open up a ticket on here.
Thank you.
08/15/2019 14:05 PM 8 days
Between the hours of 4am - 930am Eastern, Outlook users would have seen a autodiscover prompt for an account not tied to their organization (billing@travispot.com) in error. The autodiscover prompt was a result of us testing public folders for our 2016 environment and that account was one of our demo public folders. Although no users could see or open the public folder, autodiscover detected it as an available mailbox and begun to prompt users about allowing Outlook to try and connect to the public folder.
The public folder was disabled and we will investigate this further into the off hours
We have fixed the issue with Della.
The issue was attributed to some settings that were promptly enhanced in order to prevent this issue in the future.
Please verify and thank you for your patience.
07/26/2019 13:33 PM 28 days
We are currently facing some issues with the Della Server.
Please have users use LiveArchive while we pinpoint this issue.
Thank you for your patience.
New features/Options are now available in the Admin Portal:
- Ability to upload a file (csv) that contains multiple blacklist entries (domain level)
- Phishing logs (sp,domain, user level )
XDREF Feature Update
Added - When whitelisting or blacklisting, XDREF will now be adding the same rules to any alias's you may have. This includes alias's domains as well (if you're whitelisting on the Domain level)
Quick update, we continue to work on r.xdref.com as we roll out new functionality, settings, and ease of use. Here is what we did today:
- Currently working on the ability that if you whitelist or blacklist for one alias, it'll trickle down to all aliases and the main account.
- To add to that, the functionality to whitelist and blacklist items for an alias domain to trickle down to all alias domain's and the Main Domain.
- Rolled out the wild card feature we have on our standard whitelists and blacklists. Meaning you can now do an entry for :
- *.domain.com - to grab all sub-domains for the domain
- domain.com - to whitelist/blacklist the domain itself
We'll continue to update you with new features as we continue to update the service.
The issues with DELLA is fixed.
We have verified that email is flowing properly.
Again, thank you for your patience in this matter.
07/10/2019 11:32 AM 13 days
We are currently seeing some issues with DELLA.
We are looking into the issue and are working on getting it resolve ASAP.
Please standby and thank you for your patience on this issue.
Quick update, we continue to work on r.xdref.com as we roll out new functionality, settings, and ease of use. Here is what we did today:
- Reduced log databases, seeded archive log databases
- Rolled out analytics modules for frequent refresh (redirect to help in case they aren't reading the screen)
- Added more tld validations to make sure hackers can't sabotage the firewall by whitelisting all tlds (our liability)
- Exposed additional monitoring and management control panels for support for immediate remidiation
- Added additional warnings for URLs (whitelisted or not) that lead to executable content
We have been rolling out new features and fixing bugs / tweaking things on r.xdref.com all day, here is the summary so far:
- We have made the Link: window more prominent
- We have added a link to Report Issue for phishing advice & support purposes.
- We have been optimizing the search and redirect code all day, to automatically review/whitelist sites that are visited often.
- BUGFIX: Whitelist core
- BUGFIX: Email redirection, mailto: automatically redirects
- BUGFIX: Redirect on Whitelist, when client clicks to whitelist and is authenticated, system will automatically redirect
- BUGFIX: Change text from "Link:" to "Click below to proceed to the site:"
During the final phase of ExchangeDefender Phishing Firewall deployment, our whitelists briefly stopped working. This means that the users were prompted with the info screen every time they clicked on any link, good or bad, which should not be happening. An emergency patch at 2:30 PM EST was deployed and now whitelist and permitted list code is in effect.
Info: By default, ExchangeDefender Pro clients will only see the warning screen under 2 conditions: 1) Domain they clicked on is categorized as a malicious source of phishing/malware or 2) Domain is not one of the top domains on the Internet and is not on the whitelist (typically, this is where phishing content is generally directed to). For most users, warning/redirection screen should seldom be displayed.
The issues was identified as the servers were not able to boot up after hardware swap for improved performance.
This was quickly fixed and the performance of the server was enhanced.
Thank you for your patience.
06/28/2019 12:43 PM 26 days
We are getting reports of certain domains not being able to log into their sharepoint sites.
We are investigating the issue and will keep you updated.
Thank you for your patience.
The outage seems to be reported as fix about 16:00 EST yesterday.
It seems Verizon was responsible for the outage due to a widespread BGP routing leak. This affected a number of Internet services and a portion of their traffic.
BGP acts as the backbone of the Internet, routing traffic through Internet transit providers and then to services. There are more than 700k routes across the Internet. By nature, route leaks are localized and can be caused by error or through malicious intent.
Thank you for your patience in this matter.
06/24/2019 13:52 PM 30 days
It has been brought to our attention that several popular sites like Google, Amazon, Reddit, and Spectrum — just to name a few — are experiencing issues this morning. Those issues appear to have begun around 6 or 7 AM ET.
Problems appear to be clearing up as of 8:40 AM, it's likely going to take some time before everything is running smoothly again. Reports are still going up on DownDetector as of writing.
We will continue to monitor the situation as it develops.
Thank you for you patience in this matter.
If your users haven't received their scheduled Quarantine Reports, please know that you can resend the reports.
Simply log into (https://admin.exchangedefender.com) with either your SP or Domain level account.
Once there, select accounts, and find the users who are reporting that they haven't received it. Once they've been selected, click on the Actions button then click on the "Resend SPAM Report" Button.
If you're still experiencing issues with receiving SPAM Messages, please let us know and we'll be more than happy to take look into it.
06/20/2019 15:00 PM 3 days
The issue with the admin site (https://admin.exchangedefender.com) and ExchangeDefender Encryption portal (https://encryption.exchangedefender.com) has been addressed. The issue was related to some services exceeding connection counts (similar to "all circuits are busy now") in which some clients were displayed the error when the connection to the backend services could not be made. Out of abundance of caution, we put up a maintenance notice while resource adjustments were done. Everything is back to normal, mail is flowing.
Specifically, the issue was with the database facilities used for event logging. It did not affect the actual mail processing services.
The issue has been fixed. It was found out to be an issue with our hosting company.
Thank you for your patience.
06/17/2019 13:26 PM 6 days
We are currently getting error reports about phishing links redirecting to an error 503.
We are currently working on fixing the issue.
As of noon EST, the issue has been addressed and we have not seen another instance of a malware related DDoS. The problem has been addressed around 8:30 EST, fixed, put back into production for testing at 11AM and into full production around 11:30. As of 2PM EST, everything is in the clear.
For the messages that were received previously and that were affected by the DDoS, the malware scan only disarms the dangerous HTML entities. All legitimate email clients send messages in both HTML and text content, and they will show HTML version if available by default (hence why some saw the warning). To see the actual message just right click, select View Source, and you'll see the text version of it.
As of 9AM, this bug affected 117 messages of which 82 came via typical "marketing" junk source from Indeed, Constant Contact, and vresp.
We believe this problem will not show up due to a change in how we're logging and disarming these bug/tracking entities, but we will keep an eye on it as usual.
06/14/2019 13:22 PM 9 days
We are still working on the issue that was causing the problem, and have disabled the scan that was being affected in order to assure email delivery.
We are investigating and will provide an update when the problem has been resolved.
However, all mail should be arriving without an issue and without the DDoS notice.
If the message had critical / important information (in our searches it appears to have overwhelmingly affected mass mailing platforms like indeedmail, constantcontact, vresp) you can still see it by viewing the source of the message.
Just Right click, select View Source and you'll see the text version of the message.
06/14/2019 12:49 PM 9 days
We are investigating a reported issue regarding DDoS warning messages this morning as we've had a higher than usual number of messages crashing the security/antivirus engine during the scan.
Mail flow speeds have returned to normal
06/04/2019 16:40 PM 19 days
We've enabled LAX and will be smoothing out the queues between the data centers for the next 15 minutes. Mail flow should resume normal speed by 1PM Eastern
06/04/2019 15:48 PM 19 days
Our monitoring begun alerting about latency and packet loss issues with our LAX data center starting at 11:31AM. To mitigate any potential issues with delivery, we've elected to pause mail flow going to our LAX datacenter. While LAX is paused, Dallas will see mail delays up to 5 minutes but is able to handle the overall load. We will enable LAX once we see the packet loss subside.
We have received reports of a large SPAM outbreak going through our Inbound network.
The messages are of the sextortion variety and are claiming to have sensitive information/video/recordings of users and that they have to pay a Bitcoin ransom so that the perpetrators do not release the footage.
Please do not fear as the messages are benign in nature. If you or your clients are currently receiving messages like that, please open a support ticket and attach the unforwarded (we need the ORIGINAL) message in the ticket so we can analyze the headers and send you what domains to blacklist. We'll also use the message you send as a sample to track the different variants of the messages so we can create rules and enforce them immediately.
We appreciate your patience in this matter.
The issues with our DELLA Cluster has been resolved.
One of the transport hub services wasn't running properly so we had to restart the service and mail began flowing properly.
If you are still are experiencing issues with this, please let us know via a Support Ticket and we'll be more than happy to assist you.
06/03/2019 12:07 PM 20 days
We are currently facing issues with Della server.
We are investigating and fixing the issue.
Thank you for your patience.
Upgrade completed
05/30/2019 20:35 PM 23 days
At 9:00 PM Eastern we will be upgrading the Web File Server service in order to support larger downloads/uploads. The upgrade is planned to take less than 10 minutes to complete. During the upgrade, customers will receive a maintenance notification regarding WFS until the upgrade is completed.
We have currently regained powered back at our main office.
We will monitor for 24-48 hours to verify that the issue has been fixed.
Thank you for your patience.
05/30/2019 11:37 AM 24 days
We are currently facing power outages at our main office.
At the moment it's not affecting any mail flow and everything should be running as normal.
We are monitoring the situation and will update ASAP.
05/29/2019 13:36 PM 25 days
We have currently regained powered back at our main office.
We will monitor for 24-48 hours to verify that the issue has been fixed.
Thank you for your patience.
05/29/2019 12:46 PM 25 days
We are currently facing power outages at our main office.
At the moment it's not affecting any mail flow and everything should be running as normal.
We are monitoring the situation and will update ASAP.
Completed without any problems.
05/23/2019 15:39 PM 1 hrs
On Friday evening between 9PM - 11PM we will be replacing a bad disk in the LOUIE cluster which currently holds public folder data and transport service data. During the maintenance mail flow will be uninterrupted for domains that have "cas.louie.exchangedefender.com" as their delivery point for ExchangeDefender. All public folder access will be disabled during the maintenance period, however, any queued mail for the public folders will remain in queue. Regular mailbox operations will be uninterrupted.
After monitoring the network overall during our peak EST and PST hours, everything appears to be back to our normal nominal network performance, and in many cases significantly better than even our ordinary levels considering the elevated mail flow.
05/22/2019 11:20 AM 1 days
ExchangeDefender staff continued to monitor and tune our load balancing infrastructure through our cloud, particularly in our Los Angeles data center. Upgrades, improvements, and other optimizations should significantly increase performance. We will continue to monitor the situation and update this post throughout the day as we have more information but mail delivery should be significantly faster today.
05/21/2019 21:25 PM 1 days
We believe that the issues in Los Angeles have been addressed but we'll continue monitoring these systems. Nodes in this cluster were pulled in and out of production periodically while we tried to diagnose performance related issues (antivirus, DNS, routing, etc).
05/20/2019 16:29 PM 3 days
We've discovered some performance issues in the following nodes:
-Inbound19
-Inbound41
-Inbound42
Our team is currently performing emergency maintenance on those nodes.
If you're experiencing any mail delays and the NDR's are saying they're coming from those nodes, please let us know. Our team is working hard to fix the issues so the delays do not continue.,
If you have any questions or concerns, please put in a support ticket @ https://support.ownwebnow.com or give us a call @877-546-0316
We appreciate your patience in this matter.
Issue has been resolved if any denials please try again. Thank you for your patience
05/15/2019 15:21 PM 8 days
We are currently looking into errors with Reverse DNS error for some users. We will update as it develops. Thank you.
Issue has been resolved. Thank you for your patience.
05/14/2019 19:43 PM 8 days
We are currently expecting issues with incoming calls to our landlines. We are working to fix the issue. We will update as it develops.
The outages seem to be resolved. Thank you for your patience.
05/14/2019 19:41 PM 8 days
Currently Nationwide they are reported Level 3 outages. We will monitor the situation as it develops. Please expect slow response/loading times when using our system.
Thank you for your patience. The issue has been resolved.
05/13/2019 15:26 PM 10 days
We are currently experiencing some issues with one of our Sharepoint nodes on Gladstone.
Our team is currently investigating the problem and will have a resolution shortly.
If you're on Gladstone and are experiencing issues with accessing Sharepoint, please open up a support ticket and let us know the sharepoint credentials so we can validate connectivity.
The issue was fixed.
05/09/2019 12:54 PM 14 days
ExchangeDefender has received reports of several users receiving empty ExchangeDefender Quarantine SPAM reports. We are addressing the issue at the moment and will have it resolved today. In the meantime, all users can access their SPAM messages at https://admin.exchangedefender.com or by clicking on the link in the email.
We noticed an unusual high level of MAPI failed responses for a single database. We begun an active host switch over which should have immediately completed with no service interruption. Unfortunately, the mount didn't immediately finish and is still processing the switch over. This database holds 90 mailboxes. Users on this database will be unable to access their mailbox until the switch over is completed.
Service has been restored to mail1
05/01/2019 02:19 AM 22 days
We are investigating an outage on mail1.ownwebnow.com (mail1.exchangedefender.com). Currently all services are inaccessible. This affects some web hosting clients who use the POP services
This was completed without any issue
04/30/2019 17:11 PM 24 days
We will be restarting some Dallas ExchangeDefender inbound node core components at 9:45PM until 10:00 PM on 4/30/19. We will pause mail flow going to Dallas at 9:30PM to prevent any mail flow issues from occurring. Mail will continue to route through our other data centers and there will be no interruption in mail flow.
We are currently experiencing issues with our inbound phone system. If you require immediate assistance or a callback, please open a support ticket @https://support.ownwebnow.com and we'll be more than happy to assist you.
We appreciate your patience in this mattter.
The public folder issues on our LOUIE Cluster have been resolved.
If you are still experiencing issues with accessing public folders, please let us know.
We appreciate your patience in this matter.
04/24/2019 14:57 PM 30 days
We are currently having issues with accessing Public Folders on our LOUIE Cluster. Our team is currently investigating these issues ans will provide an update as soon as it's been resolved. We appreciate your patience.
We have rectified the SSL issue on our Rockeduck cluster, we appreciate your patience in the matter. If you're still encountering issues, please call us 877-546-0316 or put in a support ticket https://support.ownwebnow.com. Thank you again for your patience.
04/23/2019 15:17 PM 2 hrs
We are currently experiencing some SSL Certificate issues on our ROCKERDUCK Cluster. We have identified the issue and are currently working to resolve it. We appreciate your patience.
The issue with the Mail Delays across both the Dallas and Los Angeles Data Centers has been identified and repaired. Mail should start flowing normally within a few minutes. If you have any questions or concerns, please contact our support team via Ticket or call us at 877-546-0316. We appreciate your patience.
We have scheduled a rebalance of active hosted database distribution on our Exchange 2016 Nodes. This will have no impact on customer accessibility.
Reboots have been scheduled for LOUIEMBOX7 due to Memory issues. This is scheduled for 930PM EST today. This will have no impact on customer accessibility.
We have received two (2) client complaints about email being rejected by Comcast.
At the moment we aren't seeing issues with delivery to Comcast, none of our IP addresses on any outbound networks are on an RBL (mxtoolbox.com), and manual telnet SMTP diagnostics tests are so far showing no issues either. This leads us to believe that it's a typical Comcast issue (rejecting mail randomly from different servers as they get swamped and overloaded during peak hours). Best practices for sending mail to Comcast or Yahoo is to just resend the message and hope a different server in their infrastructure accepts the message. When there are RBL issues, we immediately open a support request and start working with their postmaster staff.
The issue was resolved and clients have reported no issues since.
04/11/2019 16:45 PM 12 days
Maintenance task has been completed and we have not seen nor have we received reports of any issues.
04/10/2019 14:00 PM 13 days
Some users on the ExchangeDefender Exchange cluster GLADSTONE experienced significant email delivery delays throughout the day as we rebalanced our storage. This is a one-time event that was a side effect of a major maintenance task required to facilitate a change in processing of our Compliance Archiving mail. Traditionally, we stored ExchangeDefender mailboxes and journal mailboxes on same volumes which during peak hours could create a performance issue, and this maintenance task assured that going forward Exchange bottlenecks will not be a source of issues for clients that remain on our legacy Exchange infrastructure.
If this issue affected your clients adversely, please schedule a migration of their mailboxes to Exchange 2016 with our team immediately and we will make sure that they are moved to the front of the queue.
ExchangeDefender LiveArchive still received and sent messages in realtime allowing our clients to not feel a major performance impact.